
Hugging Face Chat Template 정리하기


이전에는 대화형 언어 모델의 챗 템플릿(Chat Template)을 확인하려면 Hugging Face 저장소의 'Files and Versions' 탭에서 tokenizer_config.json 같은 설정 파일을 직접 찾아봐야 했습니다. 모델마다 다른 프롬프트 형식을 적용하기 위해 거쳐야 하는 다소 번거로운 과정이었습니다.
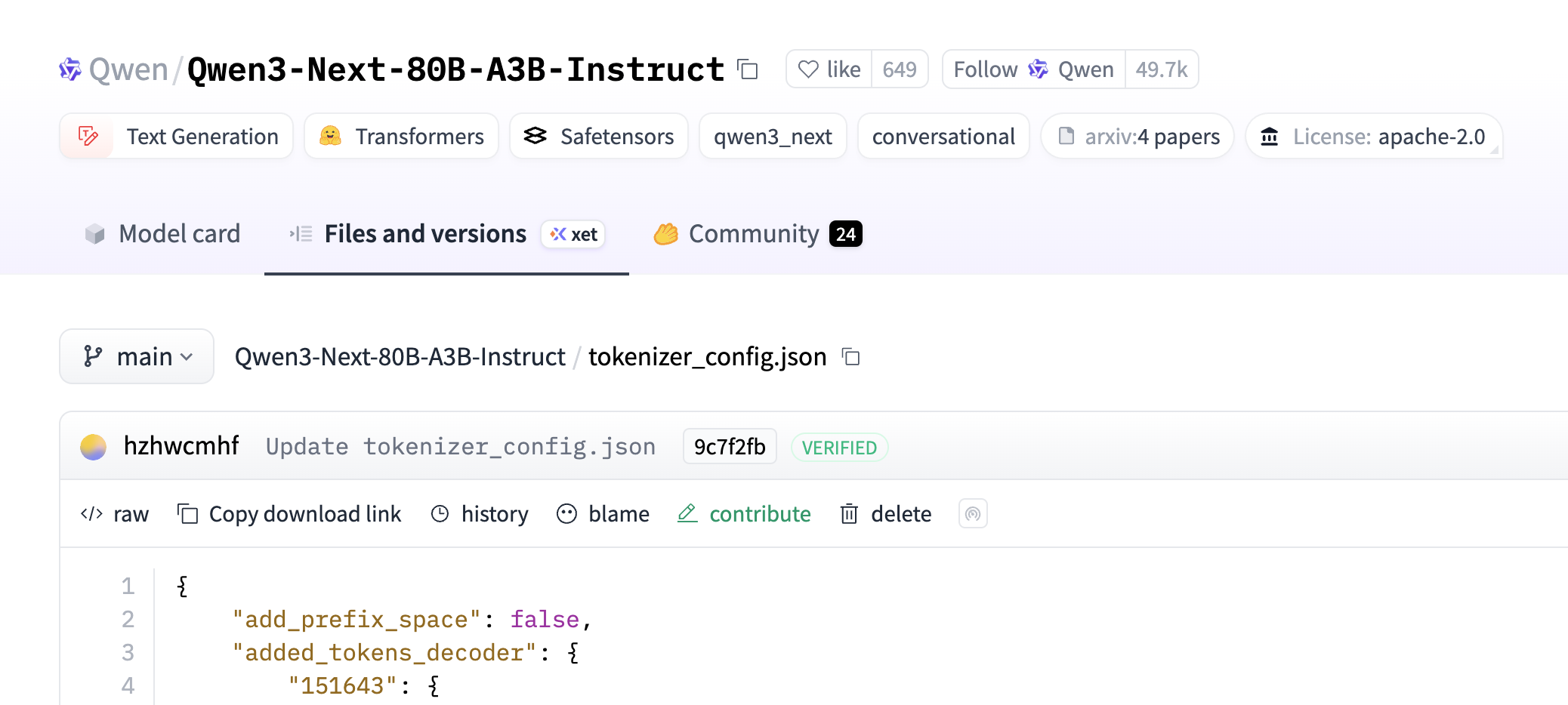
최근 허깅페이스 모델 페이지에 이 챗 템플릿을 바로 확인할 수 있는 UI가 추가된 것을 발견했습니다. 많은 사용자들이 필요로 했던 기능이 공식적으로 지원되기 시작한 것으로 보입니다. 이 기능이 언제 정확히 추가되었는지는 모르겠지만, 발견한 김에 챗 템플릿의 역할과 중요성, 그리고 기초적인 사용법을 넘어 실용적인 장점과 보안, 커스터마이징 방법까지 정리해 보았습니다.
1. Chat Template이란 무엇인가
챗 템플릿은 대화형 모델이 입력 프롬프트를 올바르게 이해할 수 있도록 정의된 구조화된 텍스트 형식입니다. 대부분의 대화형 모델은 시스템(system), 사용자(user), 어시스턴트(assistant) 등 여러 역할을 구분하여 대화의 맥락을 파악하도록 학습됩니다. 챗 템플릿은 각 역할의 메시지를 어떤 순서와 형식으로 모델에 전달해야 하는지에 대한 규칙을 명시합니다.
모델마다 파인튜닝 과정에서 사용한 템플릿이 다르기 때문에, 각 모델에 맞는 고유한 템플릿을 사용해야 합니다. 예를 들어, 어떤 모델은 <|im_start|>와 같은 특수 토큰으로 메시지를 구분하는 반면, 다른 모델은 [INST]와 같은 태그를 사용할 수 있습니다.
Chat Template 예시: Qwen3-Next
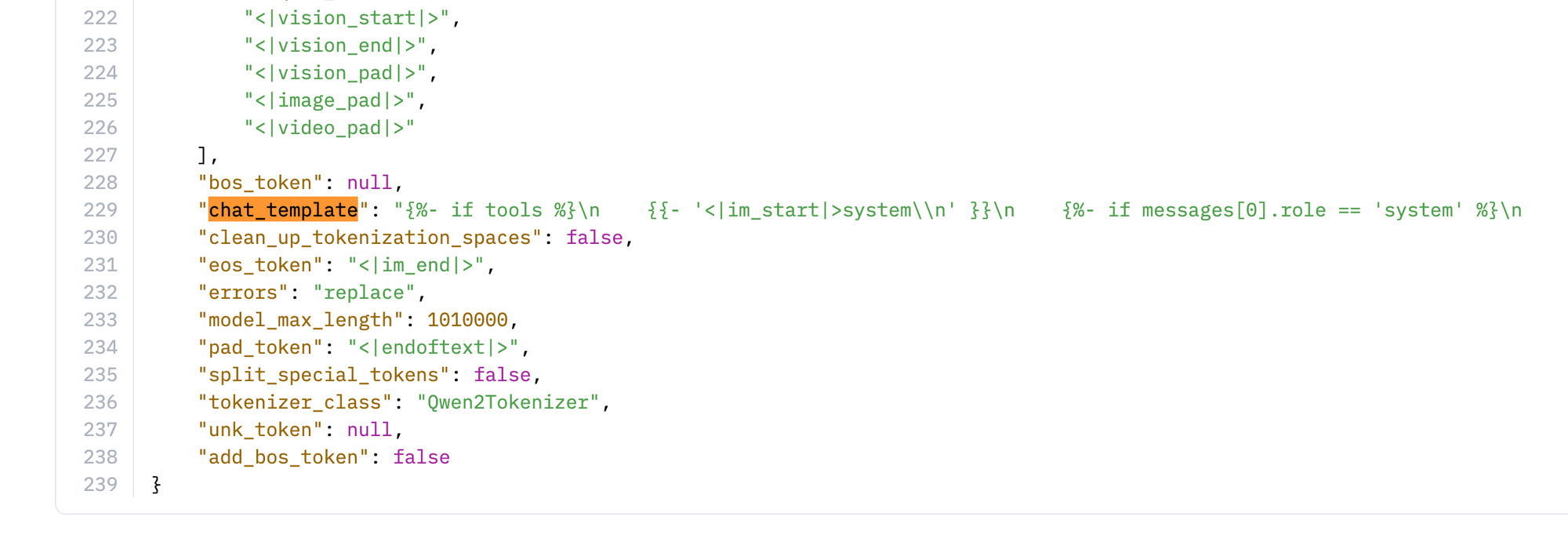
최신 모델인 Qwen3-Next의 챗 템플릿을 살펴보면 Jinja2 문법을 사용하여 매우 동적이고 복잡한 구조를 가지고 있음을 알 수 있습니다.
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0].role == 'system' %}
{{- messages[0].content + '\n\n' }}
{%- endif %}
{{- "# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0].role == 'system' %}
{{- '<|im_start|>system\n' + messages[0].content + '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if message.content is string %}
{%- set content = message.content %}
{%- else %}
{%- set content = '' %}
{%- endif %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
{{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- if message.tool_calls %}
{%- for tool_call in message.tool_calls %}
{%- if (loop.first and content) or (not loop.first) %}
{{- '\n' }}
{%- endif %}
{%- if tool_call.function %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{%- if tool_call.arguments is string %}
{{- tool_call.arguments }}
{%- else %}
{{- tool_call.arguments | tojson }}
{%- endif %}
{{- '}\n</tool_call>' }}
{%- endfor %}
{%- endif %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- endif %}
이 템플릿은 tools(함수 호출) 사용 여부에 따라 시스템 프롬프트 구조가 완전히 달라지며, 각 메시지의 역할(user, assistant, tool)에 따라 다른 형식으로 문자열을 조합하는 복잡한 로직을 담고 있습니다.
2. Chat Template이 중요한 이유
챗 템플릿을 정확히 사용하는 것은 모델의 성능에 직접적인 영향을 미칩니다.
- 모델은 특정 템플릿 형식에 맞춰 파인튜닝됩니다. 이 형식이 챗 템플릿이며, 이 형식을 준수해야 모델이 대화의 맥락과 각 메시지의 역할을 정확히 이해하고, 최적의 결과물을 생성할 수 있습니다.
- 템플릿은 시스템 지시사항, 사용자 질문, 모델의 이전 답변을 명확하게 분리하여 모델이 혼동 없이 입력을 처리하도록 돕습니다.
- 문장의 시작(BOS), 끝(EOS)을 알리는 토큰이나 모델별로 정의된 특수 제어 토큰들이 템플릿에 포함되어 있어, 모델의 입력과 출력 생성을 제어하는 데 중요한 역할을 합니다.
- 최신 모델들이 지원하는 함수 호출(Function Calling)이나 도구 사용(Tool Use) 같은 기능은 복잡한 입력 형식을 요구합니다. 챗 템플릿에는 이러한 고급 기능을 사용하기 위한 정확한 프롬프트 구조가 정의되어 있습니다.
3. 확인 및 적용 방법
Hugging Face에서 템플릿을 확인하고 코드에 적용하는 방법은 매우 간단합니다.
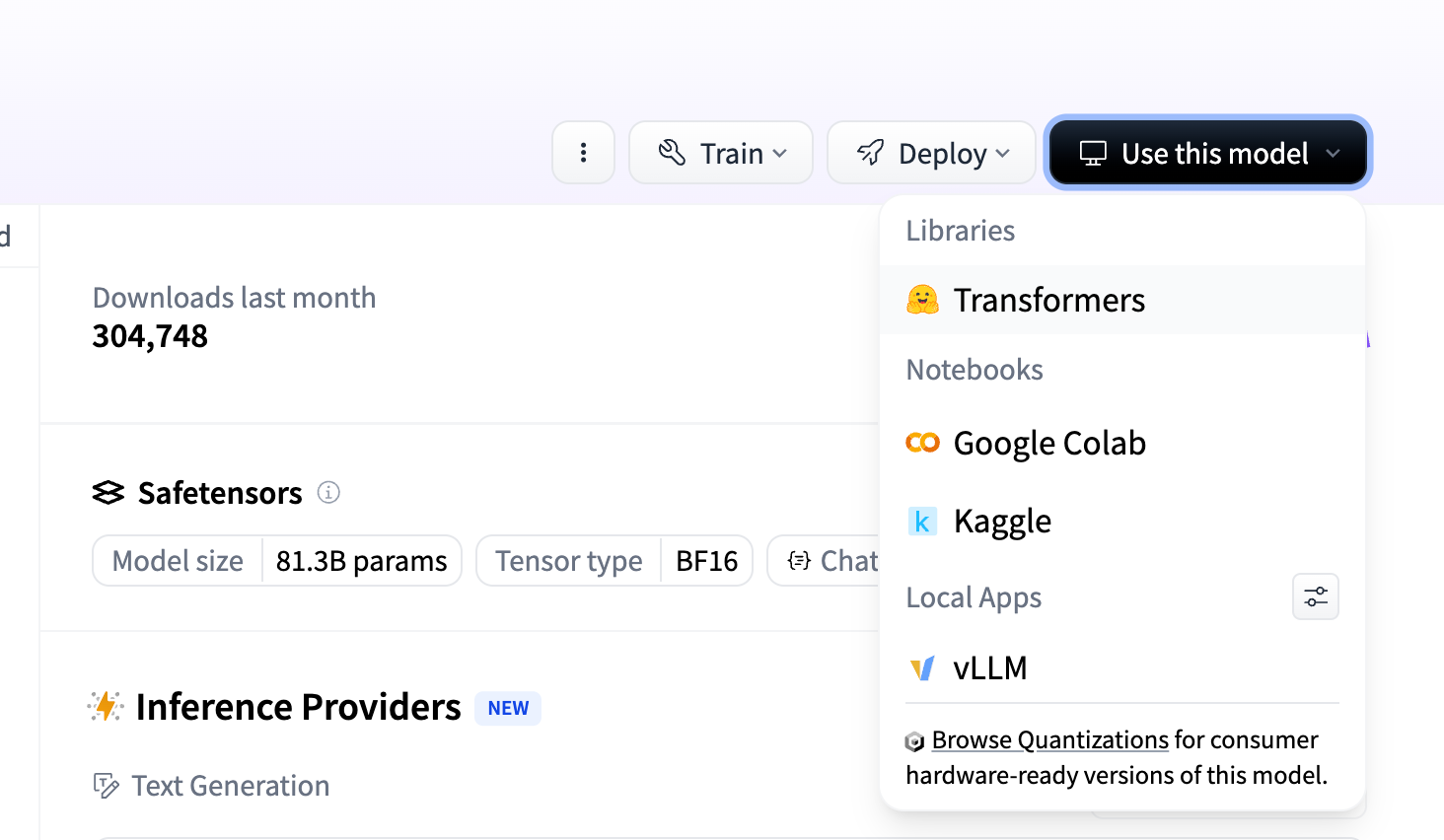
- 사용하려는 모델의 Hugging Face 페이지로 이동합니다.
- 모델 카드에서 'Use this model' 섹션을 찾습니다.
- 라이브러리 목록에서 'Transformers' 를 클릭합니다.
위 방법대로 클릭하면 transformers 라이브러리에서 해당 템플릿을 바로 사용할 수 있는 코드 스니펫이 제공됩니다.
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="Qwen/Qwen3-Next-80B-A3B-Instruct")
messages = [
{"role": "user", "content": "Who are you?"},
]
pipe(messages)# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-Next-80B-A3B-Instruct")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-Next-80B-A3B-Instruct")
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))핵심은 tokenizer.apply_chat_template() 함수입니다. 이 함수는 역할과 내용이 담긴 딕셔너리 리스트를 인자로 받아, 해당 모델의 챗 템플릿에 맞게 포맷팅된 프롬프트 문자열을 반환합니다.
4. apply_chat_template 살펴보기
apply_chat_template 함수는 단순히 문자열을 합치는 것 이상의 역할을 수행합니다.
- 자동으로 특수 토큰 처리:
bos_token(문장 시작),eos_token(문장 끝) 등 모델이 요구하는 특수 토큰을 개발자가 신경 쓰지 않아도 알아서 추가해줍니다. 이를 수동으로 처리할 때 발생할 수 있는 실수를 원천적으로 방지하여 모델의 오작동을 막습니다. - 'Generation Prompt'의 명확한 역할:
add_generation_prompt=True인수는 대화의 마지막에 '이제 모델이 답할 차례'라는 명시적인 신호를 추가합니다. 예를 들어 ChatML 형식에서는<|im_start|>assistant\n가 추가됩니다. 이 신호가 없다면, 모델은 대화가 끝났다고 인지하지 못하고 마지막 사용자 메시지에 이어서 글을 쓰는 등 예측 불가능한 행동을 할 수 있습니다. - 유지보수의 편리함: 만약 Llama 3 모델을 사용하던 코드를 Qwen 2 모델로 교체한다고 가정해 봅시다.
apply_chat_template를 사용했다면,AutoTokenizer.from_pretrained의 모델 이름만 변경하면 됩니다. 토크나이저가 새 모델의 템플릿을 자동으로 로드하여 적용하므로, 프롬프트 생성 로직을 전혀 수정할 필요가 없습니다. 이는 코드의 유연성과 확장성을 크게 높여줍니다.
5. 국내 모델 예시 - KT Mi:dm
국내에서 개발된 모델의 챗 템플릿은 어떤 특징이 있는지 KT의 Mi:dm(믿:음) 모델을 통해 살펴보겠습니다. Mi:dm의 템플릿은 모델의 정체성과 행동 지침을 정의하는 매우 상세한 시스템 프롬프트가 내장된 것이 특징입니다.
{{- bos_token }}
...
{{- '<|start_header_id|>system<|end_header_id|>\n\n' }}
{{- 'Cutting Knowledge Date: December 2024\n' }}
{{- 'Today Date: ' + date_string + '\n\n' }}
{{- 'Mi:dm(믿:음)은 KT에서 개발한 AI 기반 어시스턴트이다. 너는 Mi:dm으로서 사용자에게 유용하고 안전한 응답을 제공해야 한다.\n\n' }}
...
{{- '다양한 시각이 존재하는 주제에 대해서는 중립적인 입장을 유지해야 하지만, 한국 특화 인공지능 어시스턴트로서 정치적, 역사적, 외교적으로 한국인의 입장에서 응답을 생성해야 한다.\n' }}
...
{{- system_message }}
{{- '<|eot_id|>' }}
...
Mi:dm 템플릿의 주요 특징은 다음과 같습니다.
- 시스템 프롬프트: 템플릿은 모델의 이름, 개발사, 지식 마감일(
Cutting Knowledge Date), 그리고 현재 날짜를 프롬프트에 동적으로 삽입하여 모델이 항상 자신의 정체성과 한계를 인지하도록 합니다. - 한국 특화 정체성 부여: "한국 특화 인공지능 어시스턴트로서 한국인의 입장에서 응답을 생성해야 한다"와 같이 모델의 행동 방향을 구체적으로 지시하는 내용이 포함되어, 응답의 관점을 일관성 있게 유지합니다.
- 상세한 행동 지침: 경어체 사용, 윤리적 규범 준수 등 상세한 가이드라인이 내장되어 있어, 별도의 설정 없이도 안정적인 응답을 유도합니다.
- Llama 3 기반 토큰 사용:
<|start_header_id|>,<|eot_id|>와 같은 토큰 형식은 Llama 3의 구조를 따르고 있어, 모델의 기반 아키텍처를 짐작하게 합니다.
이처럼 Mi:dm의 템플릿은 단순한 형식 지정을 넘어, 모델의 페르소나와 정책을 코드 레벨에서부터 깊숙이 내재시키는 도구로 활용되고 있음을 알 수 있습니다.
6. Chat Template과 보안 - Template Injection
챗 템플릿이 사용하는 Jinja2 문법은 단순한 변수 치환을 넘어 조건문, 반복문 등 프로그래밍 언어의 기능을 갖추고 있습니다. 이러한 특징은 역으로 보안 위협이 될 수 있습니다.
- SSTI (Server-Side Template Injection): 만약 검증되지 않은 사용자 입력을 템플릿에 그대로 삽입하게 되면, 악의적인 사용자가 Jinja2 문법 자체를 입력값으로 넣어 서버에서 임의의 코드를 실행하려는 Template Injection 공격을 시도할 수 있습니다. 이는 심각한 보안 취약점으로 이어질 수 있습니다.
- ChatBug 취약점: 2024년 연구에서 공개된 'ChatBug'는 템플릿 구조를 역이용하는 공격입니다. 악의적인 사용자가 모델이 사용하는 특수 토큰(예:
<|im_end|>)을 사용자 메시지에 의도적으로 포함시켜 템플릿 형식을 깨뜨립니다. 이를 통해 모델의 정렬(alignment)을 우회하고, 필터링되었어야 할 유해하거나 위험한 답변을 생성하도록 유도할 수 있습니다.
따라서 Hugging Face 등 신뢰할 수 있는 출처의 모델과 템플릿을 사용하고, 사용자 입력을 템플릿과 결합할 때는 항상 잠재적인 보안 위협을 인지하고 주의를 기울여야 합니다.
7. 나만의 Chat Template 만들기
transformers 라이브러리는 기존 템플릿을 사용자를 맞게 수정하거나 완전히 새로 만드는 기능을 지원합니다.
- 기존 템플릿 수정:
tokenizer.chat_template속성에 새로운 Jinja 템플릿 문자열을 할당하면 기본 템플릿을 쉽게 덮어쓸 수 있습니다. - 커스텀 시스템 프롬프트 내장: 매번 API를 호출할 때마다 긴 시스템 프롬프트를 반복해서 넣는 것은 비효율적입니다. 아래와 같이 시스템 프롬프트를 템플릿 자체에 내장할 수 있습니다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
# 새로운 템플릿 정의 (시스템 프롬프트를 내장)
new_template = (
"{% for message in messages %}"
"{% if message['role'] == 'system' %}"
"{{ bos_token + 'You are a helpful pirate assistant who speaks in a pirate accent.\\n' }}"
"{% elif message['role'] == 'user' %}"
"{{ '<|start_header_id|>user<|end_header_id|>\\n\\n' + message['content'] | trim + '<|eot_id|>' }}"
"{% elif message['role'] == 'assistant' %}"
"{{ '<|start_header_id|>assistant<|end_header_id|>\\n\\n' + message['content'] | trim + '<|eot_id|>' }}"
"{% endif %}"
"{% endfor %}"
"{% if add_generation_prompt %}"
"{{ '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}"
"{% endif %}"
)
# 토크나이저의 템플릿 교체
tokenizer.chat_template = new_template
chat = [
{"role": "user", "content": "Who are you?"}
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
print(prompt)
- 파인튜닝과의 연관성: 모델을 특정 목적(예: 법률 자문 챗봇)에 맞게 파인튜닝할 때, 학습 데이터셋의 형식을 정의하기 위해 고유한 챗 템플릿을 설계하는 과정은 필수적입니다. 잘 설계된 템플릿은 파인튜닝의 효율과 결과물의 품질을 크게 향상시킵니다.
결론
챗 템플릿은 단순히 대화 형식을 맞추는 사소한 작업이 아니라, 모델의 성능을 최대한으로 이끌어내고, 정체성을 확립하며, 안정성을 보장하는 요소라는 것을 알아보았습니다.
apply_chat_template 함수의 기능을 활용하고, 더 나아가 그 이면에 있는 보안과 커스터마이징 가능성까지 이해한다면, 대화형 언어 모델을 더 깊이 있고 안전하게 다룰 수 있게 될 것입니다.