
프롬프트 튜닝 Prompt Tuning 살펴보기


Prompt Tuning
PEFT(Parameter-Efficient Fine-Tuning)는 적은 수의 파라미터를 학습하는것만으로 모델 전체를 파인튜닝하는 것과 유사한 효과를 누릴 수 있도록 해줍니다. PEFT 방법 중 하나인 Prompt Tuning에 대해서 알아봅시다.
참고 논문: https://arxiv.org/pdf/2104.08691.pdf
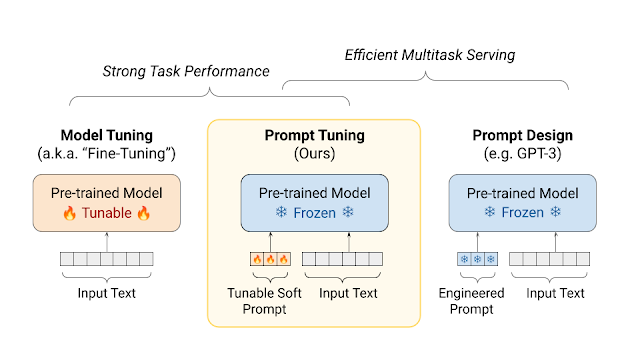
프롬프트 튜닝이란?
언어 모델을 특정 작업에 맞게 조정하기 위해 사용되는 기술입니다. 기존의 방식은 모델을 특정 작업에 맞게 전체적으로 조정해야 했지만, 프롬프트 튜닝은 모델의 핵심 부분을 그대로 유지하면서 작업 특화 부분만 조정합니다. 이는 모델의 '냉동'(frozen) 상태를 유지하면서도 필요한 부분에만 초점을 맞추어 효율성을 높이는 방법입니다.
대규모 T5 계열에서 특히 효과가 두드러지며, 수십억 파라미터 이상으로 갈수록 풀 파인튜닝과의 격차가 급격히 줄어듭니다.
작동 원리
소프트 프롬프트는 학습 가능한 ‘벡터’로 이루어져 있습니다. 이 벡터들은 입력 텍스트와 결합되어 모델의 입력으로 사용됩니다. 이 벡터들은 기존 어휘에 속하지 않는 ’가상의 토큰(virtual tokens)’으로서 작동하며, 모델의 기존 파라미터를 변경하지 않고도 특정 작업에 대한 모델의 반응을 조정할 수 있습니다. 모델은 이 입력을 기반으로 예측을 수행하고, 이 과정에서 오차를 계산하여 소프트 프롬프트를 최적화합니다. 이 방법을 통해, 다양한 작업에 대한 지식을 효과적으로 흡수하고 적용할 수 있게 됩니다.
먼저, 소프트 프롬프트를 고정 길이(e.g., 20 tokens long)의 벡터 시퀀스로 초기화합니다. 이 벡터들은 모델의 입력 텍스트 앞에 배치됩니다. Prompt 길이 P가 길수록(대체로 20 토큰 이상) 성능이 좋아지지만 100 토큰을 넘기면 이득이 줄어듭니다. 파라미터 수는 “임베딩 차원 E × P”로 선형 증가합니다.
모델이 입력을 처리할 때, 이 소프트 프롬프트 벡터들도 함께 처리됩니다. 모델이 예측을 수행하면, 예측 결과와 실제 타겟 간의 오차를 계산하여 이 오차를 사용해 소프트 프롬프트 벡터를 업데이트합니다. 이때 초기화는 “무작위”, “샘플된 어휘 임베딩”, “클래스 라벨 임베딩” 등 여러 방법이 있는데, 대형 모델(XXL)에서는 초기화 방식 간 차이가 작아집니다.
간단한 코드
import torch
import torch.nn as nn
class SoftEmbedding(nn.Module):
def __init__(self,
wte: nn.Embedding,
n_tokens: int = 10,
random_range: float = 0.5,
initialize_from_vocab: bool = True):
"""appends learned embedding to
Args:
wte (nn.Embedding): original transformer word embedding
n_tokens (int, optional): number of tokens for task. Defaults to 10.
random_range (float, optional): range to init embedding (if not initialize from vocab). Defaults to 0.5.
initialize_from_vocab (bool, optional): initalizes from default vocab. Defaults to True.
"""
super(SoftEmbedding, self).__init__()
self.wte = wte
self.n_tokens = n_tokens
self.learned_embedding = nn.parameter.Parameter(self.initialize_embedding(wte,
n_tokens,
random_range,
initialize_from_vocab))
def initialize_embedding(self,
wte: nn.Embedding,
n_tokens: int = 10,
random_range: float = 0.5,
initialize_from_vocab: bool = True):
"""initializes learned embedding
Args:
same as __init__
Returns:
torch.float: initialized using original schemes
"""
if initialize_from_vocab:
return self.wte.weight[:n_tokens].clone().detach()
return torch.FloatTensor(n_tokens, wte.weight.size(1)).uniform_(-random_range, random_range)
def forward(self, tokens):
"""run forward pass
Args:
tokens (torch.long): input tokens before encoding
Returns:
torch.float: encoding of text concatenated with learned task specifc embedding
"""
# Changes: Apply word embeddings to the entire set of input tokens without slicing
input_embedding = self.wte(tokens)
learned_embedding = self.learned_embedding.repeat(input_embedding.size(0), 1, 1)
return torch.cat([learned_embedding, input_embedding], 1)출처: https://github.com/kipgparker/soft-prompt-tuning
이 코드는 PyTorch를 사용하여 ‘SoftEmbedding’이라는 신경망 모듈을 정의합니다. 이 모듈의 주요 목적은 기존 트랜스포머 모델의 워드 임베딩(word embedding)에 추가적인 학습 가능한 임베딩을 결합하는 것입니다. 이를 통해 특정 작업에 대한 모델의 성능을 향상시킬 수 있습니다.
출처 코드에서는 input_embedding = self.wte(tokens[:, self.n_tokens:]) 로 소프트 프롬프트 토큰의 길이만큼 원본 임베딩을 잘라서 결합하였지만, 저는 원본 임베딩에 추가된 임베딩을 결합해서 사용하기 위해 다음과 같이 코드를 변경하였습니다: input_embedding = self.wte(tokens)
코드를 자세히 살펴보겠습니다.
SoftEmbedding
이 클래스는 nn.Module을 상속받아 PyTorch의 신경망 모듈로 정의됩니다.
init
wte (nn.Embedding): 기존 트랜스포머 모델의 워드 임베딩을 나타냅니다.n_tokens (int): 학습 가능한 추가 토큰의 수입니다. 이 값이 10일 때, 10개의 추가 임베딩 토큰이 생성됩니다.random_range (float): 임베딩을 초기화할 때 사용되는 범위입니다. 이 값이 0.5일 때, 각 임베딩 값은 -0.5 ~ 0.5 사이의 범위에서 무작위로 초기화됩니다.initialize_from_vocab (bool): 기존 어휘에서 임베딩을 초기화할지 여부를 결정합니다. 이 값은 아래initialize_embedding에서 어떻게 사용되는지 알 수 있습니다.learned_embedding: 특정 작업에 특화된 정보를 포함할 수 있도록 설계된 새로운 임베딩입니다. 추가적인 학습 가능한 임베딩을 정의하며, 초기화 방법은initialize_embedding메서드에 의해 결정됩니다.
initialize_embedding
- 이 메서드는 추가 임베딩을 초기화하는 데 사용됩니다.
initialize_from_vocab가True이면 기존의 워드 임베딩(wte)에서 처음n_tokens만큼을 복사하여 사용합니다. 이 방법은 기존 어휘에 기반한 임베딩을 사용하기 때문에, 모델이 이미 학습한 언어적 특성을 유지하도록 합니다.False인 경우, 지정된random_range를 사용하여 임베딩을 무작위로 초기화합니다. 이 방법은 모델이 이전에 보지 못한 새로운 종류의 데이터나 작업에 대응해야 할 때 유용합니다.
forward
- 모델이 입력 데이터를 어떻게 처리하는지 정의합니다. 이 메서드는 입력 토큰을 받아 추가적인 학습된 임베딩과 함께 원래의 워드 임베딩을 결합합니다.
tokens: 입력 데이터를 나타냅니다. 이는 모델이 처리할 원시 텍스트를 토큰화한 것입니다.learned_embedding은 모든 입력에 대해 반복되며, 기존 입력 임베딩과 연결됩니다.- 최종적으로, 학습된 임베딩과 입력 임베딩이 연결되어 반환됩니다.
SoftEmbedding을 쓸 때 주의할 점
- 토큰 자르기(slicing) 여부는 토큰화 파이프라인에 따라 달라집니다. 입력 tokens에 “가상 프롬프트 자리표시자”를 이미 넣는 방식이면 원본 임베딩에서 그 길이만큼 잘라 붙이는 패턴이 맞고, 그렇지 않고 임베딩 단계에서만 프롬프트를 주입한다면 현재처럼 전체 wte(tokens)에 단순히 프리펜드 하면 됩니다.
- 위치 임베딩/로터리 포지셔널(ROPE)을 쓰는 모델은 프롬프트 길이만큼 실제 입력의 유효 길이가 줄어든다는 점을 고려해서 max_length를 잡아야 합니다(프롬프트 + 입력 + 라벨 토큰 합이 한도를 넘지 않게).
peft, transformers 라이브러리를 활용한 예시
시작하기 전에 peft, transformers, datasets, torch 등 필요한 라이브러리를 설치합니다.
!pip install -q peft transformers datasets torch
사용할 모델과 토크나이저를 정의합니다. 이 예시에서는 bigscience/bloomz-560m을 모델과 토크나이저로 사용하였습니다. PromptTuningConfig를 정의하여 작업 유형, 가상 토큰의 수, 초기화 텍스트, 토크나이저 이름 또는 경로 등의 세부 정보를 지정합니다.
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
"/", "_"
)
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8이 예제에서는 ought/raft의 twitter_complaints라는 데이터셋을 사용합니다. 이 데이터셋은 트위터의 트윗들을 포함하고 있으며, 감정 분석이나 텍스트 분류를 위한 연구에 주로 사용됩니다. 데이터셋을 전처리하는 코드는 생략합니다. 자세한 내용은 참고 코드를 확인해주세요.
from datasets import load_dataset
dataset = load_dataset("ought/raft", dataset_name)
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
print(classes)
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
print(dataset)
dataset["train"][0]
모델을 초기화합니다. print_trainable_parameters()로 훈련 가능한 파라미터들을 확인할 수 있습니다.
# creating model
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model
모델의 파라미터를 최적화하기 위해 AdamW 옵티마이저를 사용합니다. 학습률(lr)로 학습 과정에서 얼마나 큰 단계로 가중치를 업데이트할지 결정할 수 있습니다.
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
전체 데이터셋에 대해 학습을 수행합니다. 훈련된 모델의 성능을 확인하기 위해 loss와 perplexity를 확인합니다.
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
# print(batch)
# print(batch["input_ids"].shape)
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
알아두면 좋을 것들
- 왜 규모(Scale)가 중요할까?
- 프롬프트 튜닝은 모델이 클수록 더 경쟁력이 있습니다. EMNLP 2021 결과를 보면 T5-XXL(약 110억)에서는 단 0.001–0.01% 미만의 학습 가능한 파라미터만으로도 풀 파인튜닝과 대등한 성능에 도달합니다. Prompt 길이는 대체로 20 토큰 이상에서 큰 이득이 나고, 100 이상은 체감 이득이 줄어듭니다.
- 멀티태스크 서빙
- 프롬프트만 바꿔서 여러 작업을 하나의 동결된 모델로 서빙할 수 있고, 배치 안에 서로 다른 태스크 샘플을 섞어 처리하는 “mixed-task” 서빙도 가능합니다. 이는 태스크별로 거대한 모델 복사본을 둘 필요가 없어 비용/메모리 절감에 크게 기여합니다.
- 도메인 이동(Out-of-domain)과 프롬프트 앙상블
- 동결(fronze) 덕분에 원래 모델의 언어 지식을 덜 훼손하여 도메인 이동에서 더 견고한 경향을 보입니다. 또한 하나의 태스크에 대해 여러 프롬프트를 학습해 앙상블하면, 모델 앙상블보다 파라미터/서빙 비용이 훨씬 낮으면서 성능 향상이 가능합니다.
- Prompt Tuning vs Prefix-Tuning vs P-Tuning v2
- Prompt Tuning: 입력 임베딩 앞에만 학습 가능한 가상 토큰을 붙입니다. 가장 파라미터 효율적(>10억 규모에서 <0.01%).
- Prefix-Tuning: 각 레이어에 프리픽스를 주입(내부 활성값)하여 0.1–1% 수준 파라미터를 학습합니다. 생성 과제에서 강력합니다.
- P-Tuning v2: 딥 프롬프트(레이어 전반에 주입)를 NLU 전반으로 최적화해, 0.1–3% 파라미터만으로 파인튜닝에 필적하는 성능을 보입니다.
- IA³/LoRA 등 다른 PEFT와의 관계
- IA³: 각 레이어의 내부 활성(Attn/FFN)에 학습 가능한 스케일 벡터를 곱해 억제/증폭합니다. 매우 가볍고 혼합 태스크 배치에도 유리합니다.
- LoRA: 가중치 업데이트를 저랭크로 근사합니다. 프롬프트 튜닝과 달리 본체의 “함수”를 직접 수정합니다(프롬프트는 입력 표현만 추가). 상황에 따라 LoRA가 더 강력할 때도 있지만, 저장/교체가 쉬운 건 프롬프트의 장점입니다. (PEFT는 각 방법을 통합 제공)
- 하이퍼파라미터/초기화 팁
- num_virtual_tokens: 20~100 구간으로 먼저 시도하기(너무 길면 길이 한도/지연만 늘 수 있음).
- 초기화(Init): 작은/중간 크기 모델에서는 “TEXT/클래스 라벨 임베딩 초기화”가 무작위보다 유리. XXL에서는 차이가 거의 없음.
- 학습률: [The Power of Scale for Parameter-Efficient Prompt Tuning] 논문에서 0.001~0.5 범위를 Adafactor 등과 함께 광범위하게 탐색했음(프롬프트만 학습하기 때문에 상식보다 큰 LR도 종종 안정적으로 작동).
- 데이터·라벨 마스킹 주의
- CLM 세팅에서는 손실이 프롬프트/입력 토큰에 걸리지 않게 라벨을 -100으로 마스킹하고, 라벨 토큰만 손실에 참여시키는 전처리가 흔합니다(공식 가이드 코드 참고).
- 멀티태스크 프롬프트 튜닝
- PEFT에는 MULTITASK_PROMPT_TUNING, P_TUNING, PREFIX_TUNING, IA3, LORA 등 다양한 어댑터 타입이 있습니다. 실전에서는 태스크별 프롬프트를 저장/교체하거나 혼합하는 워크플로우가 일반적입니다.
마무리
프롬프트 튜닝의 가장 큰 장점은 효율성입니다. 전체 모델을 다시 학습하지 않고도, 매우 적은 양의 파라미터만으로도 특정 작업에 대해 높은 성능을 낼 수 있습니다. 또한, 다양한 작업에 하나의 모델을 사용하여 리소스 활용도가 높아집니다. 특히 대규모 모델에서 이 방법의 효과가 크게 나타납니다.
구글 연구팀의 블로그에 따르면, 프롬프트 튜닝을 적용한 모델은 특정 도메인의 데이터로 학습한 후, 관련된 다른 도메인의 작업에 대해 ‘제로-샷’ 평가를 수행했을 때 더 높은 정확도를 보였습니다. 예를 들어, SQuAD로 학습한 후 MRQA류 OOD 데이터셋에서 튜닝 대비 이점이 관찰됩니다. 또한 “프롬프트 앙상블”의 효율도 확인됐습니다.
이러한 결과는 소프트 프롬프트 튜닝이 모델의 일반화 능력을 향상시키고, 특정 도메인에 과도하게 최적화되지 않도록 하는데 도움을 준다는 것을 시사합니다. 따라서, 언어 모델을 다양한 작업에 적용하고자 할 때 프롬프트 튜닝은 매우 유용한 도구가 될 수 있습니다. 더 자세한 정보와 연구 결과는 Guiding Frozen Language Models with Learned Soft Prompts를 참고하세요.
Reference
- Lester et al., The Power of Scale for Parameter-Efficient Prompt Tuning (EMNLP 2021).
- Li & Liang, Prefix-Tuning: Optimizing Continuous Prompts for Generation (ACL 2021).
- Liu et al., P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning (2021/2022).
- Liu et al., (IA)³: Few-Shot Parameter-Efficient Fine-Tuning (2022).
- Google Research Blog, Guiding Frozen Language Models with Learned Soft Prompts.
- Hugging Face PEFT 문서(개요/가이드/PromptTuningConfig).