
Gemma Scope 2, 대형 언어모델의 뇌를 해부하기


대형 언어모델(LLM)이 비약적으로 발전하면서 이제 연구의 초점은 단순히 성능을 높이는 것을 넘어 모델이 왜 그렇게 행동하는가에 맞춰지고 있습니다. 인공지능이 왜 할루시네이션을 일으키는지, 왜 특정 탈옥(jailbreak) 프롬프트에 취약한지, 그리고 생각하는 척하는 거짓 Chain-of-Thought 회로는 어떻게 만들어지는지 알아내기 위해서는 모델 내부를 직접 들여다볼 수 있는 정교한 도구가 필요합니다.
오늘 소개할 Gemma Scope 2는 구글 딥마인드의 최신 논문인 Gemma Scope 2: Helping the AI Safety Community Deepen Understanding of Complex Language Model Behavior에서 소개된 툴킷입니다. Gemma Scope라는 개념을 전혀 모른다는 것을 전제로, Gemma 3 모델의 내부를 해부하고 조작하기 위한 희소 오토인코더와 트랜스코더 풀 패키지에 대해 차근차근 풀어보겠습니다.
1. 왜 LLM 뇌과학이 필요할까

최근 LLM과 관련하여 발생하는 이슈들은 성능의 문제라기보다 행동의 문제에 가깝습니다. 모델이 왜 할루시네이션을 하는지, 왜 특정 프롬프트 공격에 무너지는지, 혹은 정치나 사회 이슈에서 이상하게 편향된 답을 내놓는지에 대한 원인을 찾아야 합니다. 특히 겉으로는 논리적인 척하지만 실제로는 오류를 포함하고 있는 거짓 Chain-of-Thought는 어떤 내부 회로가 만들어내는 것인지 파악하는 것이 중요합니다.
지금까지는 대부분 모델이 내놓는 결과물인 출력값만 보고 내부를 추측해왔습니다. 하지만 이제는 모델 내부의 계산 과정인 활성값(activation)을 직접 분석하고, 나아가 원인이 되는 회로를 직접 끄거나 켜보는 수준까지 발전하고 있습니다. 여기서 Gemma는 구글 딥마인드가 공개한 오픈 LLM 시리즈를 뜻하며, Gemma Scope는 이 모델 내부에 장착하여 해석과 조작을 가능하게 하는 도구 세트를 의미합니다.
2. Gemma vs Gemma Scope: 관계 이해하기
먼저 용어의 관계를 명확히 정리해보겠습니다.
Gemma 3는 구글 딥마인드의 오픈 LLM으로 270M, 1B, 4B, 12B, 27B 등 다양한 크기를 가집니다. 우리가 흔히 질문을 던지면 답변을 해주는 인공지능 모델 본체 그 자체라고 이해하면 됩니다.
Gemma Scope 2는 이 Gemma 3의 각 레이어와 서브레이어에 희소 오토인코더(SAE), 트랜스코더, 스킵 트랜스코더, 그리고 멀티 레이어용 Cross-layer 모델들을 훈련하여 붙여놓은 프로젝트입니다. 연구자들이 특정 잠재 특징인 latent를 해석하고, 해당 latent를 조작했을 때 모델의 행동이 어떻게 변하는지 실험할 수 있도록 만드는 것이 핵심 목적입니다.

비유하자면 Gemma는 인공지능의 뇌, Gemma Scope는 그 뇌에 연결된 고급 뇌파계이자 자극 장치, 그리고 뇌 내부를 상세히 들여다보는 가상 현미경이라고 볼 수 있습니다.
3. LLM 내부의 레이어와 활성값이란 무엇인가
트랜스포머 기반의 LLM 구조를 단순화하면 입력 토큰이 여러 레이어를 거치며 다음 토큰의 분포를 만들어내는 과정입니다. 각 레이어 내부에는 주의 집중을 담당하는 어텐션 블록과 복잡한 연산을 수행하는 MLP(Feedforward) 블록이 존재하며, 그 사이에는 데이터가 흐르는 잔차 연결(Residual stream)이 있습니다.
우리가 분석하려는 활성값(activations)은 레이어별 Residual 벡터와 MLP에 들어가기 전의 입력값, 그리고 MLP의 출력값들을 모두 포함합니다. Gemma Scope의 핵심 아이디어는 이 복잡한 활성값 벡터들을 해석 가능한 몇 개의 기본 특징 벡터들의 희소한 조합으로 설명하자는 것입니다. 이를 수학적으로 구현한 것이 바로 Sparse Autoencoder(SAE)입니다.
4. Sparse Autoencoder(SAE) 살펴보기
SAE는 기본적으로 희소한 중간 표현층을 가지는 오토인코더입니다.
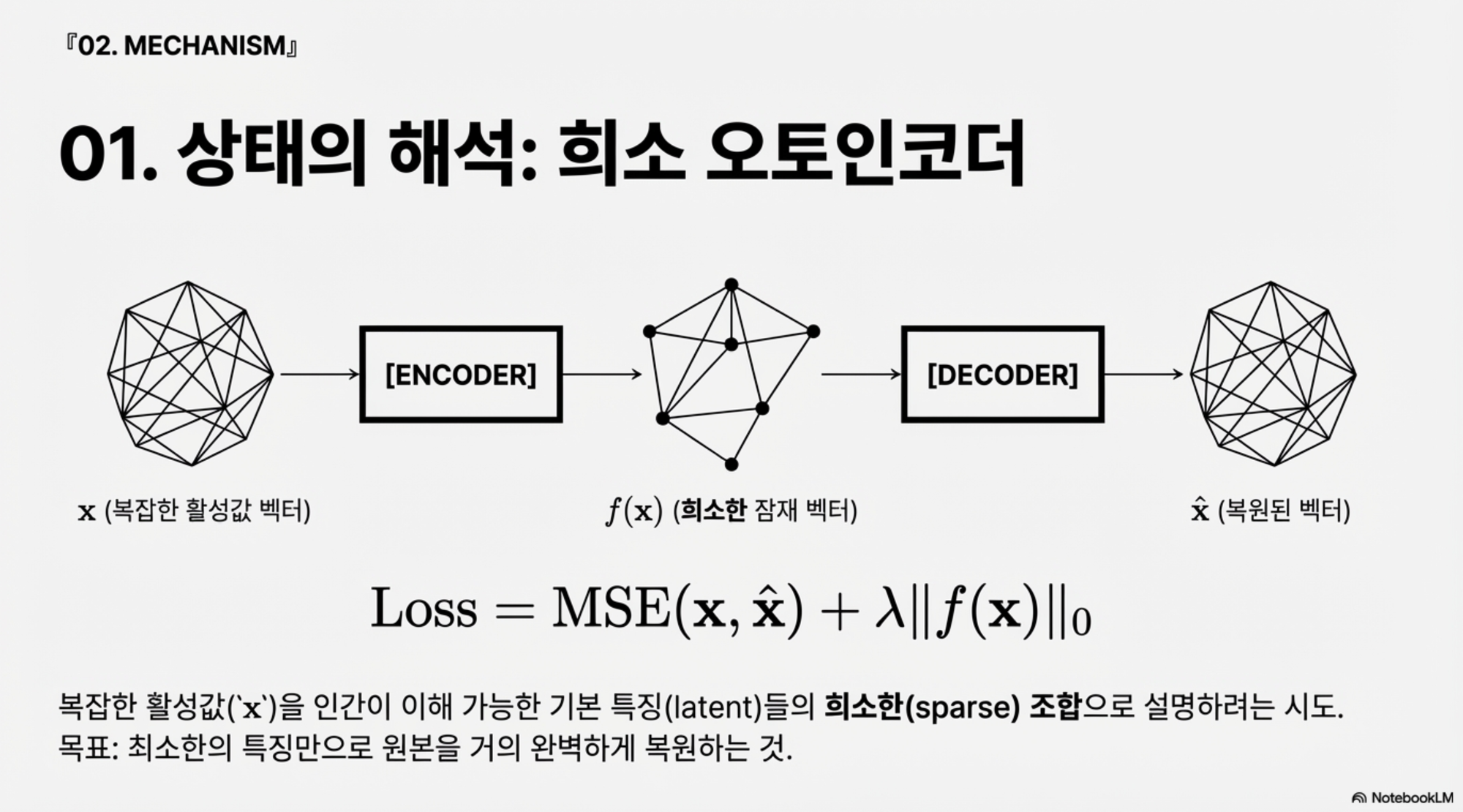
4.1 기본 구조와 목표
어떤 레이어의 활성값 $$x \in \mathbb{R}^n$$이 주어졌을 때, 인코더는 다음과 같이 작동합니다.
$$f(x) = \sigma(W_{\text{enc}} x + b_{\text{enc}})$$
여기서 생성된 잠재 벡터 $$f(x) \in \mathbb{R}^m$$은 원래 차원보다 훨씬 크지만(보통 $$m \gg n$$), 대부분의 차원이 0인 희소(Sparse)한 상태가 됩니다. 이후 디코더는 이 잠재 벡터를 다시 원래의 활성값으로 복원합니다.
$$\hat x(f) = W_{\text{dec}} f + b_{\text{dec}}$$
이 과정에서 복원 오차인 MSE와 활성화된 잠재 변수 개수에 대한 페널티인 $$L_0$$를 동시에 고려하는 손실 함수를 최소화합니다. 목표는 가능한 한 적은 수의 latent만 켜지게 하면서도 원래의 활성값을 잘 복원하는 것입니다. 이렇게 하면 디코더의 각 열인 특정 latent 방향이 특정 인물의 이름, 국가의 조합, 코딩 패턴, 혹은 욕설 템플릿과 같이 인간이 이해할 수 있는 의미 있는 특징이 됩니다.
4.2 JumpReLU: 문턱을 정하는 활성화 함수
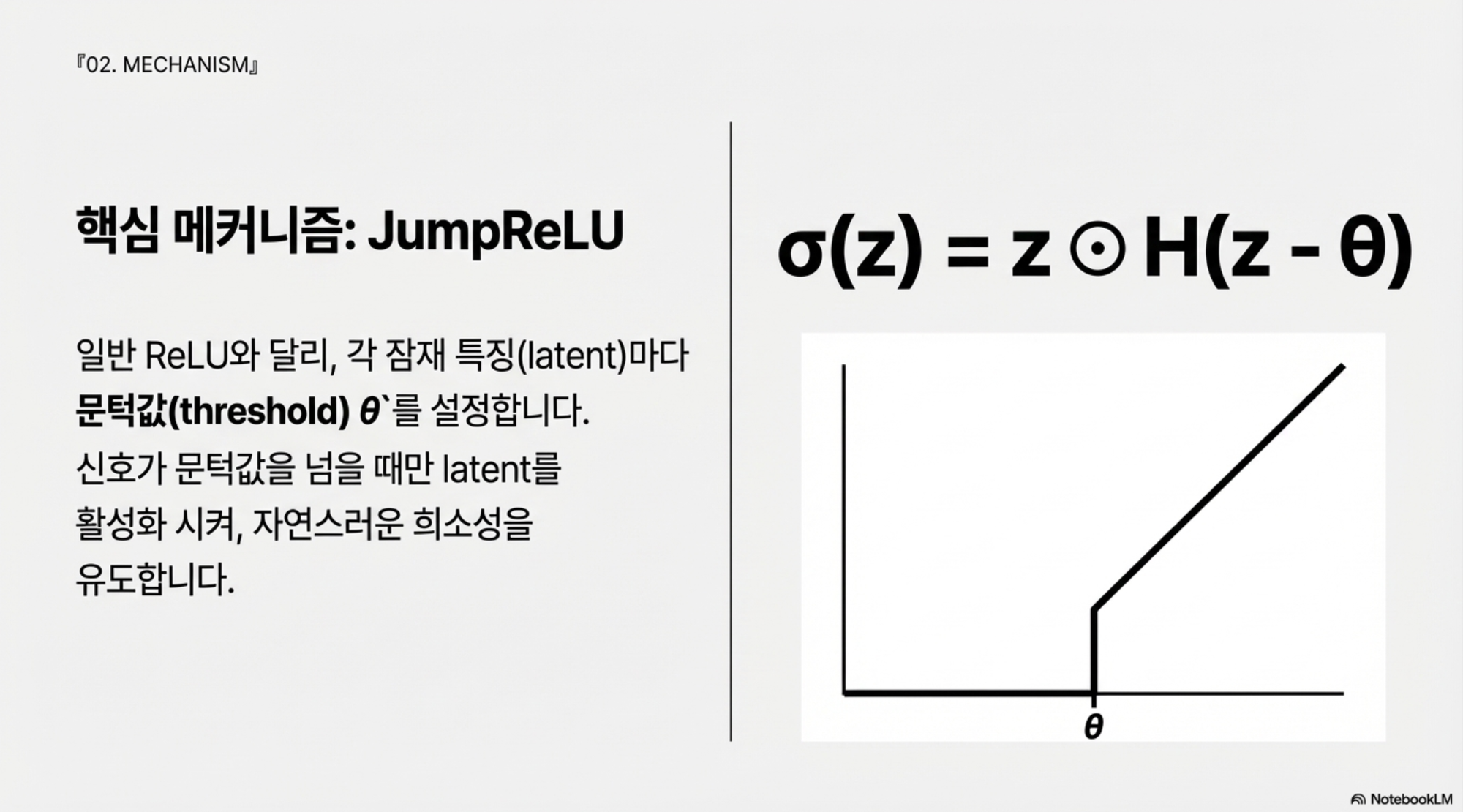
일반적인 ReLU와 달리 JumpReLU는 각 latent마다 문턱값 $$\theta$$를 설정합니다.
$$\sigma(z) = z \odot H(z - \theta)$$
신호가 문턱값보다 낮으면 완전히 0으로 만들고, 문턱값을 넘을 때만 신호를 그대로 통과시킵니다. 이는 충분히 강한 신호일 때만 latent를 켜주라는 의미를 담고 있어 자연스러운 희소성을 만들어냅니다. Gemma Scope 2의 싱글 레이어 SAE는 이 JumpReLU에 제곱형 $$L_0$$ 페널티와 실행 빈도에 대한 추가 페널티를 결합하여 성능을 개선했습니다.
5. Transcoder와 Skip Transcoder: MLP 계산의 해석
SAE가 단순히 벡터를 복원한다면, 트랜스코더는 AI 안전 관점에서 MLP가 실제로 수행하는 계산 과정을 해석하려고 시도합니다.
5.1 Transcoder의 개념
트랜스코더는 MLP에 들어가기 전의 residual 값을 입력으로 받고, MLP의 실제 출력값을 타깃으로 삼습니다. 즉, 거대한 비선형 함수인 MLP 전체를 latent들의 희소 조합으로 근사하는 것입니다. 이를 통해 특정 latent를 조작했을 때 모델의 최종 답변이 어떻게 변하는지 직접 실험할 수 있으며, 탈옥 회로와 같은 특정 행동의 핵심 원인을 정확히 짚어낼 수 있습니다.
5.2 Skip Transcoder
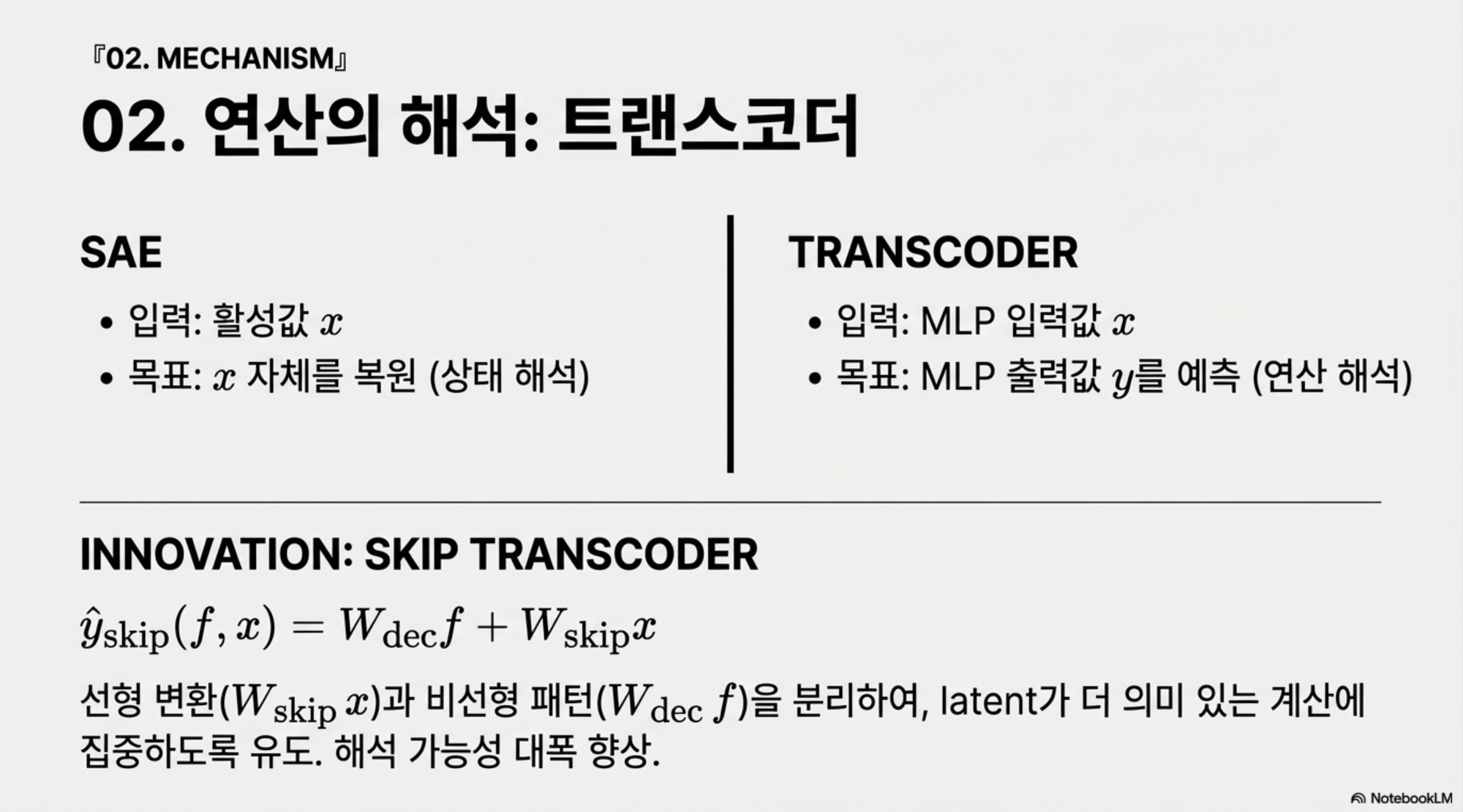
Skip Transcoder는 트랜스코더에 스킵 항을 추가한 버전입니다.
$$\hat y_{\text{skip}}(f, x) = W_{\text{dec}} f + b_{\text{dec}} + W_{\text{skip}} x$$
여기서 $$W_{\text{dec}} f$$는 정말로 새로운 의미를 담은 비선형 패턴을 담당하고, $$W_{\text{skip}} x$$는 단순한 선형 변환이나 잔차 연결에 가깝게 유지되는 부분을 처리합니다. 이렇게 역할을 분리하면 latent들이 진짜 의미 있는 새로운 계산에 집중할 수 있게 되어 해석 가능성이 대폭 향상됩니다. Gemma Scope 2는 모든 사이즈의 모델에 대해 이 스킵 트랜스코더 suite를 제공합니다.
6. 멀티 레이어 모델이 필요한 이유

지금까지의 해석 연구는 대부분 한 레이어만 보는 방식에 머물러 있었습니다. 하지만 실제 LLM 내부에서 일어나는 흥미로운 현상들은 프롬프트 해석에서 계획 수립, 행동 세부화, 출력 포맷팅에 이르기까지 여러 레이어에 걸쳐 진행되는 연쇄 계산 회로를 통해 발생합니다. 따라서 여러 레이어에 걸친 회로를 한꺼번에 보고 조작할 수 있는 멀티 레이어 모델이 중요해졌습니다.
6.1 Weakly Causal Crosscoder
여러 레이어의 활성값을 하나로 합쳐 입력으로 주되, 인코더와 디코더에 약한 인과 제약을 걸어둡니다. 인코더는 단 하나의 레이어만 보고 latent를 켤 수 있지만, 디코더는 현재 레이어와 그 이후의 미래 레이어들만 복원할 수 있습니다. 즉, 과거의 레이어를 복원하지 않음으로써 미래의 정보로 과거를 설명하는 논리적 오류를 방지합니다. 이를 통해 시간축인 레이어축을 따라 이어지는 회로를 하나의 latent 단위로 포착할 수 있게 됩니다.
6.2 Cross-layer Transcoder (CLT)
CLT는 트랜스코더의 멀티 레이어 버전입니다. 여러 레이어의 MLP 입력값들을 받아 모든 레이어의 MLP 출력 전체를 설명하려고 시도합니다. 하나의 cross-layer latent가 특정 프롬프트에서 레이어 5의 패턴을 잡고 레이어 10의 답변 스타일을 바꾸는 복합적인 역할을 담당할 수도 있습니다. 이 단계에 이르면 거짓 Chain-of-Thought를 유발하는 장거리 회로나 정책 위반 답변을 보정하는 방어 회로를 한꺼번에 분석하고 조작하는 것이 가능해집니다.
7. Gemma Scope 1 vs 2
이전 버전과 비교하여 Gemma Scope 2에서 달라진 기술적 핵심 포인트들을 정리해보겠습니다.

7.1 타깃 모델과 커버리지의 확장
기존에는 Gemma 2의 일부 레이어에만 제한적으로 도구를 제공했으나, 이제는 Gemma 3의 270M부터 27B에 이르는 모든 사이즈를 지원합니다. 전 레이어와 서브레이어에 JumpReLU SAE와 스킵 트랜스코더를 적용했으며, 일부 모델에는 멀티 레이어 전용 모델들까지 포함하여 전체 모델을 완벽하게 덮는 실험 장비를 구축했습니다.
7.2 싱글 레이어에서 멀티 레이어로의 진화
기존의 단일 레이어 SAE 중심에서 벗어나 레이어 간의 인과 구조까지 분석할 수 있는 Weakly causal crosscoder와 Cross-layer transcoder를 도입했습니다.
7.3 트랜스코더 계열의 확장
일부 MLP 블록에만 적용되던 트랜스코더를 전 레이어에 스킵 트랜스코더 형태로 제공하기 시작했습니다. 또한 멀티 레이어 버전인 CLT에도 스킵 구조를 적용할 수 있게 되었습니다.
7.4 희소성 정규화 설계의 변경
기존에는 선형 페널티나 실행 빈도 페널티를 별도로 사용했지만, 이제는 목표로 하는 희소성 수치 주변에서 제곱형으로 작동하는 Quadratic $$L_0$$ 페널티를 도입했습니다. 너무 자주 켜지는 latent에 대해서는 별도의 항으로 추가 페널티를 주어 수렴 안정성을 높이고 해석의 품질을 개선했습니다.
7.5 End-to-End(E2E) 파인튜닝 도입
기존에는 모델을 고정하고 활성값만 맞추는 방식이었으나, 이제는 SAE와 트랜스코더의 출력을 실제 모델에 꽂아 넣고 모델의 출력 분포까지 보존하도록 파인튜닝합니다.
$$\text{L} = \text{MSE} + \alpha\beta \, \text{KL} / (1 + \beta)$$
이 식에서 $$\alpha = \text{MSE} / (\text{KL} + \epsilon)$$으로 동적으로 스케일링하여 $$\beta$$ 파라미터가 KL 발산과 MSE 사이의 비율을 일관되게 조절하도록 만들었습니다. 이를 통해 모델의 실제 답변 행동까지 잘 유지하는 도구를 완성했습니다.
7.6 Instruction-tuned(IT) SAE 학습 방식의 개선
IT 모델용 SAE를 학습할 때 이전에는 별도의 데이터를 사용하거나 가중치를 이어받지 않는 경우가 많았습니다. 이제는 항상 프리트레인(PT) 모델의 SAE 가중치에서 초기화하여 학습을 시작합니다. 학습 데이터 역시 실제 오픈소스 사용자 프롬프트와 모델의 실제 롤아웃 데이터를 활용하여 PT와 IT 사이의 구조적 연속성을 유지하고 latent의 역할 변화를 추적할 수 있게 했습니다.
7.7 멀티 레이어 학습을 위한 인프라 구축
멀티 레이어 모델은 레이어 수의 제곱에 비례하는 거대한 행렬 연산이 필요하여 비용이 폭발적으로 증가합니다. 이를 해결하기 위해 실질 연산량을 레이어 수에 선형적으로 맞추는 Sparse kernel 기술과 디코더를 강하게 분산 처리하는 모델 병렬화(Sharding) 인프라를 구축했습니다. 이는 실제 규모의 Gemma 3 전체를 커버할 수 있는 실용적인 토대가 되었습니다.
7.8 BatchTopK에서 JumpReLU로의 변환
TPU에서 효율적으로 희소 연산을 수행하기 위해 학습 단계에서는 BatchTopK 방식을 사용하고, 추론이나 해석 단계에서는 이를 JumpReLU 파라미터로 변환하여 사용하는 2단계 파이프라인 구조를 선택했습니다. 학습 효율과 해석 용이성을 모두 잡은 설계라고 할 수 있습니다.
8. AI 보안에서 얻는 이점

정리하자면 Gemma Scope 2는 AI 엔지니어들에게 다음과 같은 실질적인 도움을 줍니다.
- 모든 레이어에서 블라인드 스팟 없이 회로를 찾아낼 수 있습니다.
- 레이어 3에서 시작된 패턴이 레이어 10에서 어떻게 답변을 바꾸는지와 같은 장거리 멀티 레이어 회로를 추적할 수 있습니다.
- 특정 latent를 강제로 조작하여 모델의 행동 변화를 확인하고 원인과 결과 관계를 명확히 검증할 수 있습니다.
- 프리트레인 모델과 인스트럭션 튜닝 모델 사이에서 동일한 개념이 어떻게 다르게 동작하는지 비교 분석할 수 있습니다.
- 작은 모델이 아닌 실제 서비스 규모의 Gemma 3 모델에서 작동하는 인프라를 통해 연구 결과를 현실에 바로 적용할 수 있습니다.
9. 마무리하며
활성값 복원을 넘어, 행동을 보존하는 해석 가능성으로.
Gemma Scope 2를 제대로 이해하기 위해서는 이들이 실제로 릴리즈한 도구가 무엇인지, 그리고 이 도구들로 어떤 실험이 가능한지, 마지막으로 1세대와 비교하여 무엇이 근본적으로 달라졌는지를 살펴보는 것이 좋습니다. 단순히 활성값만 맞추는 수준을 넘어 모델의 실제 출력 행동까지 유지하려는 시도와 멀티 레이어 분석을 위한 인프라 구축은 매우 큰 진전입니다.
이번 글에서는 배경 개념과 전체적인 구조를 다루었습니다. 다음 글에서는 JumpReLU SAE를 하나씩 따라가며 latent가 실제로 어떤 의미를 갖게 되는지 예시와 함께 살펴보고, 멀티 레이어 분석을 통해 가짜 CoT 회로를 어떻게 찾아내고 실험할 수 있는지를 풀어보겠습니다.