
[논문 리뷰] LLM 모델은 답하기 전에 성공 가능성을 알고 있을까?

![[논문 리뷰] LLM 모델은 답하기 전에 성공 가능성을 알고 있을까?](https://images.unsplash.com/photo-1604134774179-44e6adb65dd9?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHN3YW58ZW58MHx8fHwxNzcwODE5NjExfDA&ixlib=rb-4.1.0&q=80&w=2000)

Sparse Reward Subsystem in Large Language Models를 읽고, 내부 신뢰도 신호를 어디까지 실제 업무에 활용할 수 있을지 정리합니다.
LLM의 추론 성능은 빠르게 좋아지고 있습니다. 하지만 모델이 왜 특정 문제를 잘 풀고, 어떤 상황에서 실패하는지는 여전히 설명하기 어렵습니다. 실제 업무에서는 이 문제를 완화하기 위해 모델에게 직접 자신감을 말하게 하기도 합니다. 예를 들어 “이 답이 맞을 확률을 0부터 1 사이 숫자로 말해 달라”고 요청하는 방식입니다.
문제는 이런 자기보고식 confidence가 실제 정답 여부와 잘 맞지 않는다는 점입니다. 논문에서는 모델이 문제를 풀지 않고 confidence 숫자만 출력하도록 했을 때, Verbalized Confidence와 정답 여부 사이의 피어슨 상관계수가 0.08에 그쳤다고 보고합니다. 모델이 말로 표현하는 자신감만으로는 답변을 신뢰하기 어렵다는 뜻입니다.
이 지점에서 자연스럽게 질문이 생깁니다.
모델이 말로는 자신감을 잘 표현하지 못하더라도, 내부 표현에는 정답 가능성에 대한 신호가 남아 있지 않을까요? 그리고 그 신호를 읽을 수 있다면 LLM-as-a-judge, 라우팅, 오류 감지, 적응형 추론 예산 같은 시스템을 더 안정적으로 설계할 수 있지 않을까요?
2026년 2월 공개된 논문 Sparse Reward Subsystem in Large Language Models는 이 질문에 가까운 가설을 제시합니다. 논문의 핵심 주장은 LLM의 히든 스테이트(hidden state) 안에 보상 관련 정보가 희소하게 모여 있는 서브시스템이 있고, 그중 일부 차원은 가치(value)와 보상 예측 오차(reward prediction error, RPE)를 담고 있다는 것입니다.
이 글에서는 논문의 내용을 다음 순서로 정리합니다.
- Sparse Reward Subsystem이 무엇인지
- value neurons와 dopamine neurons를 어떻게 찾았는지
- 상위 1% value neurons 제거 실험이 왜 중요한지
- 이 결과를 범용 지능의 증거로 볼 수 있는지
- 시스템에 어떻게 적용할 수 있는지
- 적용할 때 주의해야 할 한계는 무엇인지
이 글의 결론을 먼저 정리하면 다음과 같습니다.
첫째, 이 논문은 LLM 내부에 정답 가능성을 추정하는 희소한 내적 평가 신호가 있을 수 있음을 보여줍니다. 특히 단순한 프로빙(probing)을 넘어, 특정 차원을 제거했을 때 성능이 크게 떨어지는 개입 실험까지 제시한다는 점에서 설득력이 있습니다.
둘째, 논문에서 찾은 1%의 차원을 “지능의 핵심”으로 해석하기는 조심스럽습니다. 이 신호는 지능 전체라기보다, 모델이 현재 추론 상태의 성공 가능성을 평가하는 내적 크리틱(internal critic)에 가깝게 보는 편이 안전합니다.
셋째, 실제 업무에서는 내부 confidence 기반 라우팅, 적응형 추론 예산, 온라인 오류 감지, 데이터 큐레이션, 모델 회귀 테스트에 활용할 여지가 있습니다. 다만 내부 보상 신호를 직접 최적화 대상으로 삼으면 보상 해킹 위험이 커질 수 있으므로 외부 검증기와 함께 사용해야 합니다.
1. Sparse Reward Subsystem이란 무엇인가요?
논문에서 말하는 sparse reward subsystem은 LLM의 히든 스테이트 안에 존재하는 보상 관련 신호의 희소한 부분집합입니다. 여기서 보상은 일반적인 강화학습의 보상처럼, 최종 답이 맞는지 틀리는지에 가까운 신호로 이해할 수 있습니다.
논문은 이 서브시스템 안에 두 가지 유형의 차원이 있다고 설명합니다.
- Value neurons: 현재 상태가 최종적으로 좋은 결과를 낼 기대값을 담는 차원입니다.
- Dopamine neurons: 예측한 보상과 실제 보상 사이의 차이, 즉 보상 예측 오차(RPE)를 담는 차원입니다.
여기서 “neuron”이라는 표현은 생물학적 뉴런을 뜻하지 않습니다. LLM의 히든 벡터 안에 있는 특정 차원(dimension)을 가리키는 표현입니다. 논문이 생물학적 보상 시스템과의 유사성을 언급하긴 하지만, 이를 곧바로 뇌의 뉴런과 같은 실체로 해석하면 안 됩니다.
논문은 LLM의 생성 과정을 강화학습 관점으로 다시 봅니다.
- 상태(state): 지금까지의 입력과 생성된 토큰들
- 행동(action): 다음 토큰을 생성하는 선택
- 보상(reward): 최종 답이 맞으면 1, 틀리면 0과 같은 결과 신호
핵심은 모델이 답을 모두 생성한 뒤에야 성공 여부를 알 수 있는 것이 아니라, 답을 생성하기 전의 초기 상태에서도 어느 정도 성공 가능성을 내부적으로 평가하고 있을 수 있다는 점입니다.
실험에는 GSM8K, MATH500, Minerva Math, ARC, MMLU-STEM 같은 수학·추론·지식 벤치마크가 사용되었습니다. 특히 규칙 기반 보상으로 RLVR을 수행한 SimpleRL-Zoo 계열 모델들이 주요 실험 대상으로 포함됩니다.
이 지점에서 조심해야 할 부분도 있습니다. 논문에서 말하는 value는 대부분 “정답일 가능성”에 가깝습니다. 현실 서비스에서 말하는 유용성(helpfulness), 안전성(harmlessness), 인간 선호(preference) 같은 복합적인 가치 함수와는 다를 수 있습니다.
또 하나 중요한 점은 히든 스테이트의 좌표계 문제입니다. 어떤 정보가 특정 차원에 담겨 있다고 해서, 그 차원 자체가 항상 본질이라고 단정하기는 어렵습니다. 표현 공간을 회전하거나 다른 방식으로 재구성하면 같은 정보가 여러 차원의 조합으로 나타날 수도 있습니다. 따라서 이 논문은 “특정 모델의 표현 좌표계에서 보상 관련 정보가 매우 희소하게 나타났다” 정도로 해석하는 편이 안전합니다.
2. Value probe와 pruning으로 value neurons를 찾는 방법

논문은 value neurons를 찾기 위해 value probe를 사용합니다.
프로빙(probing)은 모델의 히든 스테이트에 어떤 정보가 들어 있는지 작은 보조 모델로 읽어내는 방법입니다. 이 논문에서는 각 레이어의 히든 스테이트를 입력으로 받아 최종 보상을 예측하는 작은 MLP를 value probe로 사용합니다.
여기서 중요한 질문은 “무엇을 예측하는가?”입니다. 이 논문에서 value probe가 예측하는 것은 최종 정답 여부입니다. 즉, 현재 상태의 히든 스테이트만 보고 이 추론이 최종적으로 맞을 가능성이 높은지 낮은지를 예측합니다.
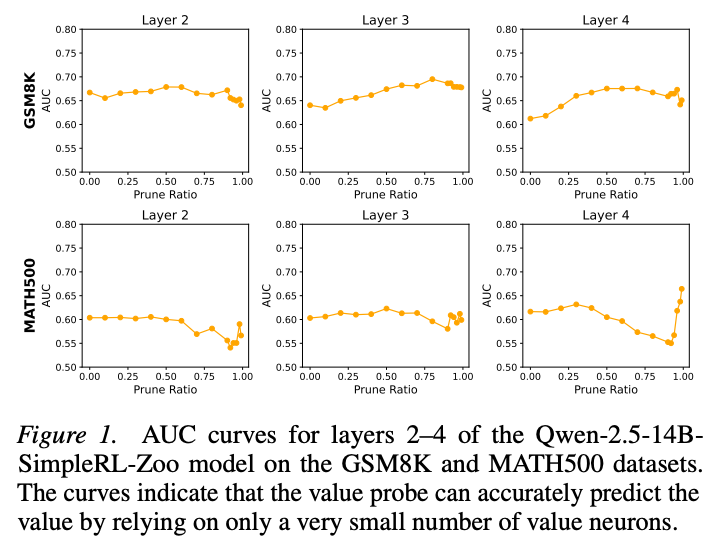
논문의 전체 절차는 다음과 같습니다.
첫째, value probe를 일부러 단순하게 만듭니다. 논문에서는 2-layer MLP와 ReLU를 사용합니다. 프로브가 너무 복잡하면 히든 스테이트에 들어 있던 정보를 읽는 것이 아니라, 프로브가 자체적으로 문제를 풀어버릴 수 있습니다. 단순한 프로브를 쓰는 이유는 예측 성능이 프로브의 학습 능력보다 히든 스테이트 안의 구조적 정보를 반영하도록 만들기 위해서입니다.
둘째, Temporal Difference, 즉 TD 방식으로 학습합니다. TD 학습은 현재 가치 예측이 다음 시점의 가치 예측과 일관되도록 맞추는 방식입니다. 마지막 토큰에서는 실제 보상, 즉 정답이면 1이고 오답이면 0인 값과 맞추고, 중간 단계에서는 시간에 따른 가치 변화가 자연스럽게 이어지도록 TD error를 줄입니다.
셋째, 평가는 답을 생성하기 전의 초기 상태에서 수행합니다. 모델이 답을 모두 생성한 뒤의 히든 스테이트를 보는 것이 아니라, 문제를 받은 직후의 히든 스테이트에서 value를 뽑아냅니다. 그리고 이 값이 최종 정답과 오답을 얼마나 잘 구분하는지 AUC로 평가합니다.
넷째, pruning으로 정보의 희소성을 확인합니다. 입력 차원 중 중요도가 낮은 차원을 제거해도 AUC가 유지된다면, 정답 가능성 정보가 전체 히든 스테이트에 넓게 퍼져 있는 것이 아니라 소수 차원에 집중되어 있다는 근거가 됩니다. 논문은 프로브 1층 가중치의 L1 norm이 작은 입력 차원부터 제거합니다.
결과적으로 논문은 1% 미만의 차원만으로도 value를 예측할 수 있다고 보고합니다. 이 부분이 논문의 핵심 주장 중 하나입니다. 모델 내부의 보상 관련 정보가 전체 표현에 넓게 퍼져 있는 것이 아니라, 매우 희소한 부분집합에 집중되어 있을 수 있다는 뜻입니다.
(다만 L1 norm 기반 pruning이 유일한 방법은 아닙니다. mutual information, integrated gradients, activation patching 같은 다른 기준을 쓰면 다른 차원 집합이 나올 수 있습니다. 따라서 이 결과를 더 강하게 주장하려면, pruning 기준이 바뀌어도 비슷한 구조가 유지되는지 확인할 필요가 있습니다.)
3. 상위 1% value neurons 제거 실험이 중요한 이유
프로빙만으로는 “히든 스테이트에 정보가 있다”는 상관관계까지만 보여줄 수 있습니다. 하지만 그 정보가 실제 추론에 중요한지는 별도의 개입 실험이 필요합니다.
논문은 특정 레이어에서 value probe가 중요하다고 판단한 상위 1% value neurons를 제거합니다. 여기서 제거한다는 것은 해당 차원의 activation을 0으로 만드는 방식입니다. 그리고 같은 비율의 랜덤 차원을 제거한 경우와 비교합니다.
핵심 질문은 단순합니다.
value neurons는 그저 정답 가능성을 읽어낼 수 있는 차원일까요? 아니면 실제 추론 과정에 중요한 역할을 하는 차원일까요?
논문에서 제시된 대표적인 결과는 Qwen-2.5-7B-SimpleRL-Zoo와 MATH500 조합에서 나타납니다.

- 원래 정확도: 75.2%
- 랜덤 1% 차원 제거: 74.6%
- 상위 1% value neurons 제거: 20.3%
특정 레이어에서는 더 극단적인 결과도 보고됩니다. 예를 들어 Layer 5에서 상위 value neurons를 제거했을 때 정확도가 1.2%까지 떨어졌다고 합니다.
이 결과는 단순한 프로빙 결과보다 훨씬 강한 의미를 가집니다. 랜덤하게 같은 비율의 차원을 제거했을 때는 성능이 거의 유지되지만, value neurons로 식별된 차원을 제거하면 추론 성능이 크게 떨어지기 때문입니다.
다만 이 결과를 “1%의 차원이 지능 전체를 담당한다”는 식으로 해석하면 과합니다. 더 조심스러운 해석은 이렇습니다. 이 차원들은 모델의 추론 과정에서 성공 가능성을 평가하거나, 계산 경로를 조절하는 병목 신호에 가까울 수 있습니다. 즉, 지능 전체라기보다 모델이 “지금 이 추론이 잘 진행되고 있는지”를 내부적으로 판단하는 평가 회로에 가까워 보입니다.
특정 레이어에서 유독 성능 하락이 크게 나타나는 점도 흥미롭습니다. 이는 모델의 초기 연산 단계에서 성공 가능성에 따라 이후 계산 흐름이 달라질 수 있음을 시사합니다. 하지만 이 부분 역시 추가 검증이 필요합니다. 레이어별 민감도가 모델 구조, 학습 방식, 태스크 유형에 따라 얼마나 안정적으로 유지되는지 확인해야 합니다.
4. 이 1%를 범용 지능이라고 부를 수 있을까요?
논문을 읽으면서 가장 먼저 떠오르는 질문은 이것입니다.
“이 1%가 범용 지능의 핵심인가?”
현재 논문이 직접 보여준 것은 범용 지능이라기보다 다음 세 가지에 가깝습니다.
- 정답 또는 오답의 기대값을 담는 희소한 신호가 있습니다.
- 이 신호는 추론 성능에 원인적으로 중요한 역할을 할 수 있습니다.
- 이 신호의 위치는 일부 태스크와 모델 변형 사이에서 어느 정도 안정적으로 공유됩니다.
논문은 이 안정성을 보기 위해 IoU, 즉 intersection-over-union을 사용합니다. 서로 다른 태스크나 모델에서 찾은 value neurons 집합이 얼마나 겹치는지 확인하는 방식입니다.
예를 들어 같은 모델에서 태스크만 바꿔도 IoU가 랜덤 베이스라인보다 높게 나타납니다. 또한 pruning ratio가 99%에 가까워질수록, 즉 더 핵심적인 차원만 남길수록 태스크 간 뉴런 겹침이 더 뚜렷해진다고 보고합니다. GSM8K와 ARC 비교에서도 99% pruning 조건에서 IoU가 0.6보다 크다는 결과가 언급됩니다.
같은 베이스 모델에서 RLVR로 파인튜닝한 서로 다른 모델 간에도 IoU가 랜덤보다 높게 나타납니다. 이는 특정 문제를 푸는 구체적인 지식은 흩어져 있을 수 있지만, “이 문제가 잘 풀리고 있는지”를 판단하는 내부 평가 구조는 어느 정도 공유될 수 있음을 시사합니다.
그래도 이 결과를 곧바로 범용 지능의 증거로 보기는 어렵습니다. 논문에서 다루는 보상은 주로 정답 여부입니다. 수학 문제를 맞혔는지, 벤치마크 문제의 정답을 냈는지에 가까운 신호입니다. 현실 세계의 지능은 정답성뿐 아니라 장기 계획, 도구 사용, 사회적 맥락, 안전성, 선호 충돌, 불확실성 처리까지 포함합니다.
따라서 이 연구는 “지능의 코어를 찾았다”기보다 “LLM 내부에 정답 가능성을 평가하는 희소한 내적 크리틱의 단서가 있다”는 쪽으로 읽는 편이 적절합니다.
5. Value neurons는 어떻게 쓸 수 있을까요?
실제 환경에서 가장 중요한 질문은 이것입니다.
모델이 답을 내놓기 전에 이미 내부적으로 알고 있을 수 있는 성공 가능성을 서비스에 어떻게 활용할 수 있을까요?
논문이 제시하는 대표적인 응용은 크게 두 가지입니다.
첫째, value neurons를 이용해 더 신뢰할 수 있는 confidence를 추출하는 것입니다.
논문에서는 세 가지 confidence 신호를 비교합니다.
- Verbalized Confidence: 모델에게 자신감을 숫자로 말하게 하는 방식
- Next-token Probability: 다음 토큰 확률을 confidence로 보는 방식
- Value Neurons: 히든 스테이트에서 직접 추출한 value 신호
Verbalized Confidence는 정답 여부와의 상관이 낮았습니다. Next-token Probability도 전체 문제의 성공 가능성을 잘 대변하지 못했습니다. 반면 value neurons 기반 신호는 정답 여부와 더 높은 상관을 보였습니다. 논문에서는 value neurons 기반 신호가 Spearman 상관 0.47 수준을 보였다고 보고합니다.
이 결과는 모델이 말로 표현하는 자신감보다, 내부 히든 스테이트에서 읽은 신호가 실제 정답 가능성과 더 잘 맞물릴 수 있음을 시사합니다.
둘째, dopamine neurons를 이용해 추론 과정 중의 보상 예측 오차를 감지하는 것입니다.
논문은 value 예측과 실제 보상이 어긋나는 지점에서 RPE 신호를 담는 차원을 dopamine neurons라고 부릅니다. 이 표현도 생물학적 뉴런을 뜻하는 것이 아니라, 생물학적 보상 시스템과의 기능적 유사성을 빌린 이름입니다.
논문에서 말하는 dopamine neurons는 다음과 같은 패턴을 보입니다.
- 예상보다 결과가 좋을 때 활성화가 높아집니다.
- 예상보다 결과가 나쁠 때 활성화가 낮아집니다.
- 추론 중간 단계의 성공 가능성 변화와 관련된 신호로 해석할 수 있습니다.
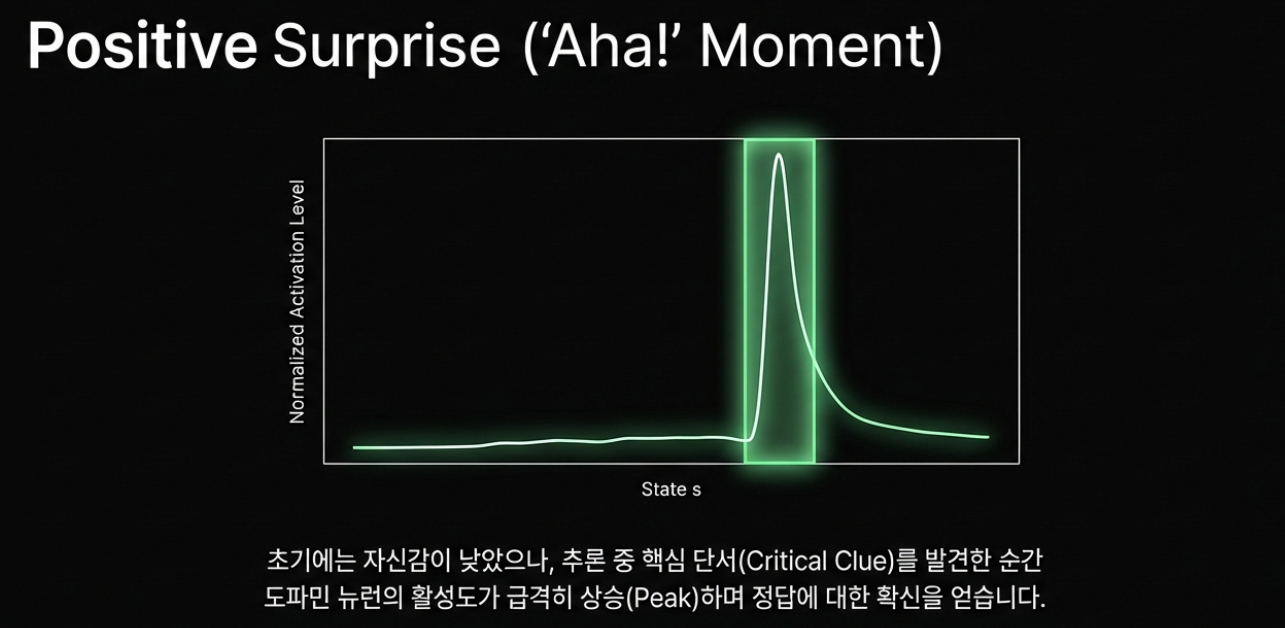
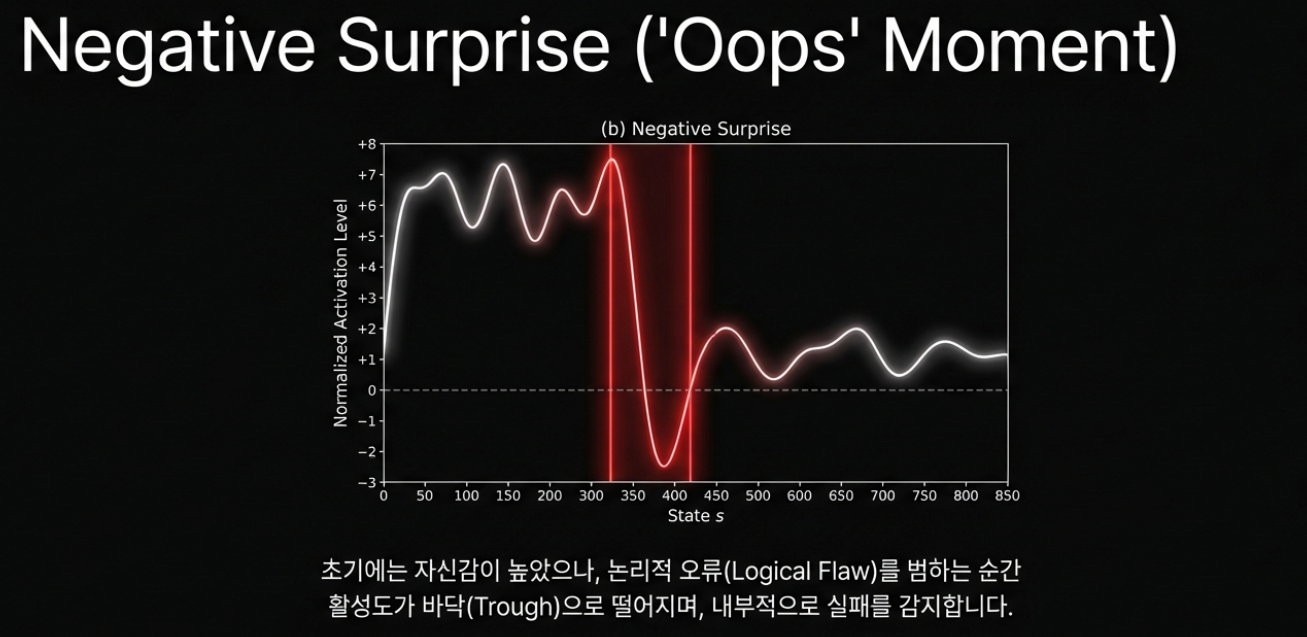
6. 업무 적용 아이디어
이 논문을 실제 서비스 설계 관점에서 보면, 몇 가지 활용 방향이 떠오릅니다.
6.1 Confidence 기반 라우팅
가장 직접적인 활용은 라우팅입니다. 모델이 답을 생성하기 전에 내부 value 신호를 읽고, 이 값이 낮으면 더 강한 모델이나 추가 검증 단계로 넘깁니다.
예를 들어 다음과 같은 정책을 만들 수 있습니다.
- value가 높으면 현재 모델이 바로 응답합니다.
- value가 중간이면 검색, 계산기, 코드 실행기 같은 도구를 호출합니다.
- value가 낮으면 상위 모델로 라우팅하거나 사람 검토로 에스컬레이션합니다.
이 방식의 핵심은 모델이 말로 표현한 confidence가 아니라, 히든 스테이트 기반 confidence를 정책 입력으로 사용한다는 점입니다.
6.2 적응형 추론 예산
모든 요청에 같은 추론 예산을 쓰는 것은 비효율적입니다. 쉬운 문제에는 짧게 답하고, 어려운 문제에는 더 많은 계산을 쓰는 방식이 필요합니다.
value 신호를 사용하면 다음과 같은 정책을 만들 수 있습니다.
- value가 높으면 짧은 추론으로 바로 답합니다.
- value가 낮으면 Chain-of-Thought를 길게 사용합니다.
- value가 낮으면 best-of-N 또는 majority voting 횟수를 늘립니다.
- value가 낮으면 별도 검증 모델을 호출합니다.
- value가 낮으면 self-correction 루프를 실행합니다.
이렇게 하면 비용과 지연 시간을 줄이면서도, 어려운 요청에는 더 많은 계산을 배정할 수 있습니다.
6.3 온라인 오류 감지와 백트래킹
Dopamine neurons가 추론 과정 중의 RPE 신호를 담고 있다면, 생성 중 오류 감지에도 활용할 수 있습니다.
예를 들어 Chain-of-Thought 생성 중 특정 단계에서 negative surprise가 감지되면, 그 지점에서 추론이 잘못된 방향으로 가고 있을 가능성이 있습니다. 이때 출력을 그대로 이어가기보다 다음과 같은 조치를 취할 수 있습니다.
- 현재 추론 경로를 중단합니다.
- 이전 단계로 돌아가 다른 경로를 탐색합니다.
- 검증기를 호출해 해당 단계의 오류 여부를 확인합니다.
- 같은 문제를 다른 방식으로 다시 풀게 합니다.
이 접근은 단순한 사후 검증보다 더 세밀합니다. 답이 모두 생성된 뒤 틀렸는지 확인하는 것이 아니라, 추론이 무너지는 시점을 중간에 감지하려는 시도이기 때문입니다.
6.4 내적 캘리브레이션 기반 데이터 큐레이션
실제 업무에서 중요한 데이터는 모델이 헷갈리는 데이터입니다. 특히 모델이 자신만만하게 틀리는 사례는 매우 가치가 높습니다.
value 신호와 실제 보상을 함께 보면 다음과 같은 데이터를 구분할 수 있습니다.
- High Value, High Reward: 모델이 자신 있게 맞힌 사례
- Low Value, Low Reward: 모델이 어렵다고 느꼈고 실제로 틀린 사례
- Low Value, High Reward: 모델이 불확실했지만 맞힌 사례
- High Value, Low Reward: 모델이 자신 있게 틀린 사례
이 중 High Value, Low Reward 데이터는 미세 조정(fine-tuning)이나 평가 데이터로 특히 중요할 수 있습니다. 모델의 근거 없는 자신감을 교정하는 데 유용하기 때문입니다.
6.5 다목표 내부 크리틱
현실 서비스에서 중요한 것은 정답성만이 아닙니다. 답이 맞더라도 안전하지 않거나, 사용자의 의도에 맞지 않거나, 불필요하게 장황할 수 있습니다.
따라서 value probe를 하나만 두기보다, 여러 목표에 대한 내부 크리틱을 분리하는 방향을 생각해볼 수 있습니다.
예를 들어 다음과 같은 프로브를 둘 수 있습니다.
- 정답성(correctness) 프로브
- 안전성(safety) 프로브
- 유용성(helpfulness) 프로브
- 정책 준수(policy compliance) 프로브
- 불확실성(uncertainty) 프로브
이 경우 모델이 답변을 생성하기 전에 내부 신호들이 서로 충돌하는지 볼 수 있습니다. 정답성 신호는 높지만 안전성 신호가 낮다면, 바로 응답하지 않고 추가 검증이나 가드레일을 통과시키는 방식입니다.
6.6 모델 모니터링과 회귀 테스트
모델 업데이트 후 표면적인 벤치마크 점수가 같더라도, 내부 판단 구조는 바뀔 수 있습니다. 이때 value neurons의 위치, IoU, 활성 패턴 변화를 추적하면 모델의 내부 동작 변화를 더 빨리 감지할 수 있습니다.
예를 들어 업데이트 전후로 다음을 비교할 수 있습니다.
- value neurons 집합이 얼마나 유지되는지
- 특정 태스크에서 value 신호 분포가 바뀌었는지
- confidence calibration이 악화되었는지
- 특정 레이어의 민감도가 달라졌는지
- dopamine-like signal이 오류 지점에서 여전히 반응하는지
이런 지표는 기존 accuracy나 win rate만으로 보기 어려운 변화를 포착하는 데 도움이 될 수 있습니다.
7. 적용할 때의 한계와 주의점
이 논문은 흥미로운 방향을 제시하지만, 바로 제품 시스템에 적용하기에는 몇 가지 제약이 있습니다.
7.1 히든 스테이트 접근이 필요합니다
value neurons와 dopamine neurons를 활용하려면 모델의 히든 스테이트나 activation에 접근해야 합니다. 오픈소스 모델을 직접 서빙하는 환경에서는 가능하지만, API 기반 상용 모델에서는 구현이 어렵거나 불가능할 수 있습니다.
따라서 이 접근은 현재 기준으로는 로컬 추론, 자체 서빙, 온프레미스 모델 운영, 연구용 모델 분석 환경에서 더 현실적입니다.
7.2 도메인 시프트를 검증해야 합니다
수학 벤치마크에서 잘 작동하는 value 신호가 고객지원, 법률, 의료, 코딩, 문서 요약에서도 같은 의미를 가진다고 보장할 수는 없습니다.
특히 현실 서비스의 “정답”은 벤치마크처럼 명확하지 않은 경우가 많습니다. 고객지원 답변은 정답성이 아니라 정책 준수, 친절함, 맥락 이해, 리스크 회피가 함께 중요합니다. 의료나 법률 영역에서는 안전성과 책임 문제가 더 큽니다.
따라서 value 신호를 실제 상황에 적용하려면 도메인별 calibration과 별도 평가가 필요합니다.
7.3 내부 보상을 목적함수로 직접 최적화하면 위험합니다
가장 조심해야 할 부분은 보상 해킹입니다. 내부 value 신호가 정답 가능성과 잘 맞는다고 해서, 이를 그대로 최적화 목표로 삼으면 모델이 실제 정답성보다 내부 점수를 올리는 방향으로 학습될 수 있습니다.
이는 외부 보상 모델에서도 발생하는 문제입니다. 모델이 평가 지표의 허점을 이용하면, 점수는 올라가지만 실제 품질은 떨어질 수 있습니다.
따라서 내부 value 신호는 단독 목적함수보다 보조 신호로 쓰는 편이 안전합니다. 외부 검증기, 정답 기반 평가, 사람 평가, 정책 가드레일과 함께 사용해야 합니다.
7.4 모델과 학습 방식에 따라 달라질 수 있습니다
논문은 여러 데이터셋과 모델 변형에서 안정성을 보고하지만, 모든 모델에 같은 구조가 존재한다고 단정하기는 어렵습니다. 모델 크기, 사전학습 데이터, RLVR 여부, instruction tuning 방식, 아키텍처에 따라 value neurons의 위치와 성격은 달라질 수 있습니다.
따라서 활용 시에는 “이 논문에서 찾은 레이어와 차원을 그대로 가져다 쓰는 방식”보다, 사용하는 모델과 도메인에 맞춰 다시 프로빙하고 검증하는 방식이 필요합니다.
8. 이 논문을 어떻게 읽어야 할까요?
이 논문은 LLM 내부에 “정답 가능성을 평가하는 신호”가 있을 수 있음을 보여준다는 점에서 흥미롭습니다. 특히 희소한 차원 집합을 찾고, 그 차원을 제거했을 때 성능이 크게 떨어진다는 개입 실험까지 제시했다는 점이 중요합니다.
하지만 이 결과를 과하게 일반화할 필요는 없습니다. 논문에서 말하는 value는 주로 정답 여부에 가까운 보상입니다. 또한 neuron이라는 표현은 생물학적 실체가 아니라 히든 벡터의 특정 차원입니다. 따라서 “LLM 내부에서 범용 지능의 핵심 1%를 찾았다”는 식의 해석은 조심해야 합니다.
더 적절한 해석은 이렇습니다.
LLM 내부에는 현재 추론이 성공할 가능성을 평가하는 희소한 내적 신호가 있을 수 있습니다. 이 신호는 모델의 자기보고 confidence보다 실제 정답 여부와 더 잘 맞물릴 수 있고, 일부 조건에서는 추론 성능에 원인적으로 중요한 역할을 할 수 있습니다.
업무 관점에서는 이 신호를 confidence 기반 라우팅, 적응형 추론 예산, 온라인 오류 감지, 데이터 큐레이션, 회귀 테스트에 활용할 수 있습니다. 다만 외부 검증 없이 내부 신호만 믿는 것은 위험합니다. 내부 보상은 좋은 보조 지표가 될 수 있지만, 최종 품질과 안전성을 보장하는 독립적인 검증 체계가 함께 필요합니다.
9. 결론
Sparse Reward Subsystem in Large Language Models는 LLM 내부에 내적 가치 추정(value estimation) 신호가 희소하게 존재할 수 있고, 그 일부가 추론 성능에 중요한 역할을 할 수 있음을 보여주는 연구입니다.
특히 상위 1% value neurons 제거 실험에서 성능이 크게 떨어지고, 랜덤 제거에서는 성능이 거의 유지된 결과는 이 논문의 핵심 근거입니다. 또한 value neurons가 자기보고 confidence보다 정답 여부와 더 잘 맞는 신호가 될 수 있다는 점은 의미가 있습니다.
다만 이 결과를 범용 지능의 핵심으로 해석하기에는 아직 이릅니다. 이 논문이 다루는 보상은 주로 정답 또는 오답이고, neuron도 생물학적 뉴런이 아니라 히든 벡터의 차원입니다. 더 안전한 결론은, LLM 내부에 추론 성공 가능성을 평가하는 희소한 내적 크리틱의 단서가 있다는 것입니다.
앞으로 이 방향은 모델 해석 가능성 연구뿐 아니라, LLM 서비스 운영에도 연결될 수 있습니다. 모델이 답하기 전에 내부 신뢰도 신호를 읽고, 그 신호에 따라 검증·라우팅·추론 예산을 조절하는 시스템은 충분히 실용적인 연구 주제입니다.
중요한 것은 내부 신호를 “정답”으로 믿지 않는 것입니다. 내부 value는 좋은 위험 신호가 될 수 있지만, 최종 판단은 외부 검증, 도메인 평가, 안전 가드레일과 함께 이루어져야 합니다.
참고 링크
- Sparse Reward Subsystem in Large Language Models (arXiv:2602.00986) (arXiv)
- SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning… (arXiv:2503.18892) (arXiv)
- Training Verifiers to Solve Math Word Problems (GSM8K) (arXiv:2110.14168) (arXiv)
- Let’s Verify Step by Step (process supervision / MATH500 맥락) (arXiv:2305.20050) (arXiv)