
멀티 에이전트 시스템에서 먼저 설계해야 하는 것


최근 OpenRouter가 Fusion이라는 기능을 공개했습니다. 여러 모델이 같은 질문에 답하고, judge 모델이 그 답변들을 읽은 뒤 하나의 결과로 합성하는 방식입니다. OpenRouter는 deep research 벤치마크에서 이 구조가 단일 frontier 모델보다 더 높은 점수를 냈다고 설명했습니다.
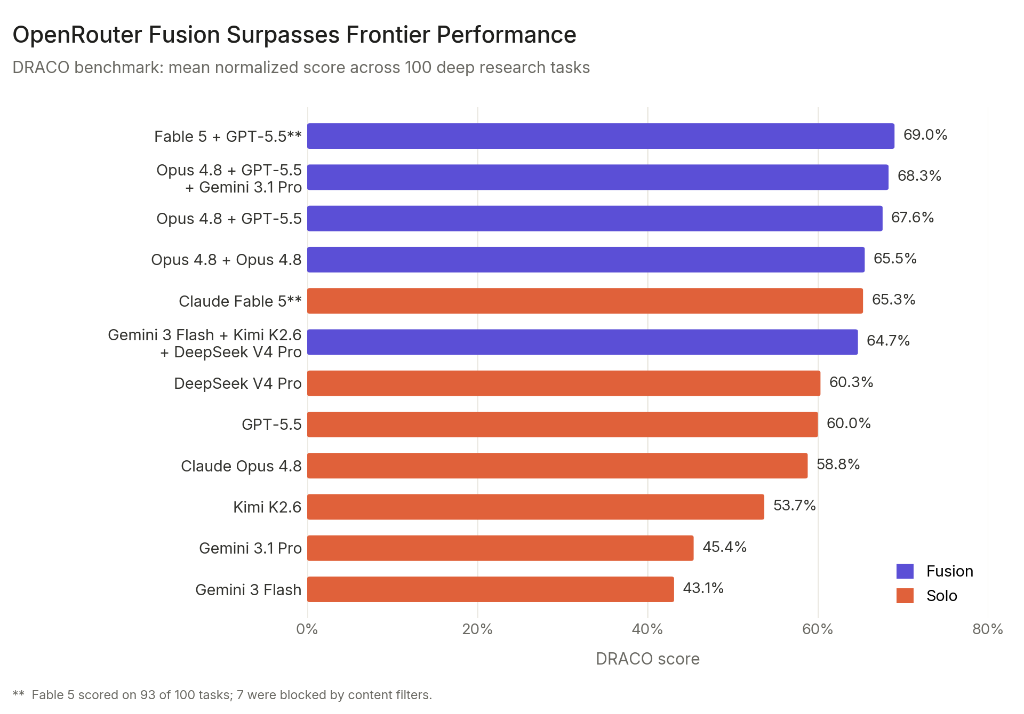
이 발표에서 눈에 들어온 부분은 “여러 모델을 붙였더니 성능이 올랐다”는 결과 자체보다, 성능을 올리는 방식이었습니다. 모델 하나가 바로 최종 답을 내는 구조에서 벗어나, 여러 답변을 비교하고, 충돌을 보고, 빠진 지점을 찾고, 마지막에 합성합니다.
LLM 제품을 만들다 보면 자연스럽게 모델 선택에 집중하게 됩니다. 어떤 모델이 가장 똑똑한지, 비용은 얼마나 드는지, 응답 속도는 어떤지, 한국어는 잘하는지, 코딩은 어느 정도 하는지 같은 질문이 먼저 나옵니다. 이 질문들은 여전히 중요합니다. 다만 실제 업무 시스템에서는 다른 문제가 곧 따라옵니다.
- 모델이 낸 답이 왜 맞는지 알기 어렵습니다.
- 어떤 요구사항이 빠졌는지 확인하기 어렵습니다.
- 그럴듯한 답변 안에 숨어 있는 위험을 찾기 어렵습니다.
- 다시 실행했을 때 같은 품질이 나올지도 애매합니다.
OpenRouter Fusion 같은 구조는 이 지점에서 의미가 있습니다. 여러 모델을 병렬로 호출하는 기능 자체보다, 결과를 비교하고 판단하는 단계가 제품 설계의 중심으로 올라온다는 점이 중요합니다.
멀티에이전트 시스템을 만들 때도 같은 문제가 생깁니다. 에이전트 수를 늘리는 것은 쉽습니다. 기획자, 개발자, 보안 전문가, 운영 담당자, 품질 검토자 같은 이름을 붙이면 금방 그럴듯한 구조가 나옵니다. 문제는 이름만 다른 에이전트들이 실제로는 같은 질문을 비슷한 방식으로 풀고 있을 수 있다는 점입니다.
멀티에이전트가 필요한 작업과 그렇지 않은 작업
멀티에이전트 구조는 모든 작업에 필요한 구조가 아닙니다. 사용자 요청이 명확하고, 필요한 도구가 적고, 하나의 컨텍스트 안에서 판단할 수 있는 작업이라면 단일 에이전트에 좋은 도구 설명과 검증 단계를 붙이는 편이 더 낫습니다.
멀티에이전트를 사용해야 하는 작업은 조금 다릅니다.
- 여러 방향을 동시에 탐색해야 한다.
- 각 방향이 서로 다른 자료나 도구를 봐야 한다.
- 충돌, 누락, 근거 부족을 드러내는 것이 중요하다.
- 최종 결과를 사람이 검토하고 수정해야 한다.
- 결과의 가치가 추가 비용과 지연 시간을 감당할 만큼 크다.
예를 들어 간단한 문서 요약은 단일 모델로 충분할 수 있습니다. 반면 여러 문서의 최신본 여부, 권한, 데이터 매핑, 정책 리스크, 운영 검증까지 함께 판단해야 하는 업무 자동화 설계라면 단일 모델 호출만으로는 놓치는 지점이 많아집니다.
flowchart TD
A[사용자 요청] --> B{여러 방향을 동시에 봐야 하는가?}
B -- 아니오 --> C[단일 에이전트 + 검증 단계]
B -- 예 --> D{각 방향이 다른 자료나 도구를 보는가?}
D -- 아니오 --> E[강한 모델 다회 샘플링 + merge]
D -- 예 --> F{결과 가치가 비용과 지연 시간을 감당하는가?}
F -- 아니오 --> G[Router / Skill / 경량 워크플로우]
F -- 예 --> H[멀티에이전트 구조 적용]
H --> I[실패 지도 작성]
I --> J[관점 카드 설계]
J --> K[독립 실행]
K --> L[Judge / 충돌 정리]
L --> M[근거 포함 최종 산출물]페르소나는 시작하기 쉽지만
멀티에이전트 시스템을 처음 설계하면 대부분 페르소나부터 나눕니다.
너는 기획자입니다. 요구사항을 분석하세요.
너는 개발자입니다. 구현 가능성을 검토하세요.
너는 보안 전문가입니다. 보안 리스크를 검토하세요.
너는 운영 담당자입니다. 운영 이슈를 검토하세요.
이 방식은 단순해서 시작하기 쉽습니다. 모델에게 특정 역할을 주면 답변의 초점이 조금 바뀝니다. 보안 전문가라고 하면 보안 이야기를 더 하고, 개발자라고 하면 구현 이야기를 더 합니다.
문제는 여기서 멈출 때 생깁니다.
역할 이름은 다른데 입력은 같습니다. 질문도 같습니다. 출력 형식도 같습니다. 사용한 모델도 같습니다. 그러면 답변은 생각보다 빨리 비슷해집니다. “요구사항을 명확히 해야 한다”, “권한 관리가 필요하다”, “테스트가 필요하다”, “운영 모니터링이 필요하다” 같은 말이 여러 에이전트에서 반복됩니다.
특히 또 문제가 되는 지점은 다음과 같습니다.
- 과제별로 좋은 페르소나가 다르다.
- 사후적으로 가장 좋은 페르소나를 고르면 이득이 있어 보일 수 있지만, 실제 사용 시 사전에 올바른 페르소나를 선택하기 어렵다.
- 과제와 관계없는 세부 정보가 추론 방식과 답변 분포를 바꿀 수 있다.
- “전문가”라는 이름이 실제 추가 지식이나 새로운 검증 능력을 제공하지는 않는다.
이런 구조에서는 에이전트가 많아질수록 시스템이 똑똑해지기보다 장황해집니다. 사용자는 더 많은 텍스트를 받지만, 실제로 새롭게 발견된 문제는 많지 않습니다.
멀티에이전트 시스템의 품질은 에이전트 개수로 결정되지 않습니다. 각 에이전트가 서로 다른 실패를 얼마나 잘 잡는지가 더 중요합니다.
독립된 관점으로 생각하기
페르소나는 “누구처럼 생각할 것인가”에 가깝습니다. 독립된 관점은 “무엇을 실패로 볼 것인가”에서 출발합니다.
예를 들어 “보안 전문가”라는 페르소나를 주면 모델은 일반적인 보안 조언을 할 가능성이 큽니다.
민감정보 보호가 필요합니다.
접근 권한을 관리해야 합니다.
감사 로그를 남겨야 합니다.
권한별 정책을 분리해야 합니다.
틀린 말은 아니지만 실제 설계에 바로 반영하기에는 추상적입니다. 여기서 필요한 것은 보안 전문가라는 이름보다, 보안 관점이 반드시 찾아야 하는 실패 목록(= 제약 조건)입니다.
다음 실패만 찾는다.
1. 사용자 권한보다 넓은 문서 접근
2. 승인자 없는 배포
3. 출처 없는 답변 생성
4. 민감정보가 포함된 문서의 무단 사용
5. 감사 로그로 추적할 수 없는 작업
이렇게 쓰면 에이전트의 움직임이 좁아집니다. 좁아진 만큼 결과가 선명해집니다. “보안도 중요합니다” 같은 문장 대신, 어떤 설계 결정이 어떤 위험을 만드는지 지적할 수 있습니다.
같은 방식으로 데이터 관점도 만들 수 있습니다.
다음 실패만 찾는다.
1. 고객 문서의 필드가 시스템 스키마에 매핑되지 않음
2. 같은 의미의 용어가 여러 이름으로 섞여 있음
3. 최신본과 구버전을 구분할 수 없음
4. 표, 각주, 이미지 안의 정보가 누락됨
5. 필수 필드가 비어 있어 자동화가 중간에 멈춤
운영 관점은 또 다릅니다.
다음 실패만 찾는다.
1. 배포 후 결과 품질을 측정할 방법이 없음
2. 실패했을 때 원인을 추적할 로그가 없음
3. 사용자가 잘못된 결과를 수정할 수 없음
4. 재실행 시 같은 기준이 적용되지 않음
5. 승인과 롤백 절차가 없음
이렇게 나누면 각 관점이 서로 다른 오류를 봅니다. 역할 이름보다 중요한 것은 “이 관점이 놓치면 어떤 문제가 실제로 터지는가”입니다.
입력도 독립적으로
프롬프트만 바꿔서는 한계가 있습니다. 여러 에이전트가 같은 문서 전체를 보고 같은 질문에 답하면 답변이 쉽게 겹칩니다.
관점을 제대로 나누려면 각 에이전트가 우선적으로 보는 자료도 달라야 합니다.
요구사항 관점:
- 사용자 요청
- 회의록
- 기존 업무 흐름
- 최종 사용자의 역할
문서/데이터 관점:
- 업로드 문서
- 문서 메타데이터
- 컬럼명과 필드명
- 용어집
- 최신본 여부
보안 관점:
- 권한표
- 조직도
- 개인정보 처리 기준
- 감사 정책
구현 가능성 관점:
- 사용 가능한 도구 목록
- API 제약
- 시스템이 지원하는 기능
- 배포 환경의 제한사항
운영 검증 관점:
- 테스트 질문
- 정답 근거
- 실패 사례
- 평가 기준
- 로그와 모니터링 항목
자료가 달라지면 질문도 달라집니다. 질문이 달라지면 발견하는 실패도 달라집니다.
예를 들어 같은 “문서 기반 질의응답 앱을 만들어줘”라는 요청을 보더라도 관점마다 보는 지점이 달라야 합니다.
요구사항 관점은 누가 이 앱을 쓰는지, 어떤 상황에서 쓰는지, 답변 이후 어떤 행동이 이어지는지 봅니다.
문서/데이터 관점은 문서가 충분히 구조화되어 있는지, 최신본이 무엇인지, 표나 이미지 안의 정보가 빠지지 않는지 봅니다.
보안 관점은 사용자가 볼 수 없는 문서까지 검색되는지, 민감정보가 답변에 노출될 수 있는지 봅니다.
구현 가능성 관점은 현재 시스템의 노드, 도구, API로 실제 구현 가능한지 봅니다.
운영 검증 관점은 배포 이후 답변 품질을 어떻게 측정할지, 실패를 어떻게 재현할지 봅니다.
이 정도로 갈라져야 각 관점의 결과가 최종 산출물에 따로 기여합니다.
flowchart TD
U[사용자 요청 / 문서 / 제약 조건] --> F[실패 지도 작성]
F --> R[요구사항 관점 카드]
F --> D[문서·데이터 관점 카드]
F --> S[보안 관점 카드]
F --> I[구현 가능성 관점 카드]
F --> O[운영 검증 관점 카드]
R --> R1[독립 분석 결과]
D --> D1[독립 분석 결과]
S --> S1[독립 분석 결과]
I --> I1[독립 분석 결과]
O --> O1[독립 분석 결과]
R1 --> J[Judge]
D1 --> J
S1 --> J
I1 --> J
O1 --> J
J --> C{충돌 / 누락 / 근거 부족?}
C -- 있음 --> Q[필요한 관점에만 재질문]
Q --> J
C -- 없음 --> P[최종 산출물 패키지]
P --> A[최종 답변]
P --> E[근거 맵]
P --> H[가정 목록]
P --> X[충돌 지점]
P --> K[리스크]
P --> V[검증 체크리스트]
P --> W[재실행 가능한 워크플로우]출력 형식
여러 에이전트가 각자 긴 글을 쓰면 마지막에 합성하는 모델이 많은 일을 떠안습니다. 무엇이 결론이고, 무엇이 근거이고, 무엇이 추측인지 다시 해석해야 합니다. 이 과정에서 중요한 지적이 묻히거나, 근거 없는 주장이 최종 답변에 섞일 수 있습니다.
관점마다 출력 형식을 정해두면 judge가 훨씬 안정적으로 동작합니다.
보안 관점은 이렇게 출력할 수 있습니다.
{
"risk": "사용자 권한보다 넓은 문서 접근 가능성",
"evidence": "요청에는 부서별 접근 차이가 언급되어 있으나 설계안에는 문서 권한 분리가 없음",
"severity": "high",
"fix": "문서 저장소를 부서별로 분리하고 사용자 그룹 기반 접근 정책을 추가",
"unknowns": ["실제 조직 권한표 미제공"]
}
운영 검증 관점은 아래 처럼,
{
"test_case": "영업팀 사용자가 인사 문서에 대해 질문한다",
"expected": "권한 부족 안내 또는 접근 불가 처리",
"required_evidence": ["문서 ACL", "사용자 그룹 정보"],
"failure_condition": "인사 문서 내용을 요약해 답변함"
}
요구사항 관점은 이렇게 쓸 수 있습니다.
{
"requirement": "배포 전 승인자가 결과물을 검토해야 함",
"source": "사용자 요청의 '검토 후 배포' 표현",
"explicit_or_implicit": "explicit",
"missing_detail": "승인자 역할과 승인 기준이 정의되지 않음"
}
출력 형식이 잡혀 있으면 judge는 각 답변을 비교할 수 있습니다. 공통 결론, 충돌 지점, 근거 부족, 추가 확인 필요 항목을 구조적으로 다룰 수 있습니다.
여기서 judge의 역할은 여러 관점의 결과를 감사하고, 어떤 지적을 반영할지 고르는 역할입니다.
judge가 보존해야 하는 것
judge를 단순하게 결과를 합치는 모듈로 두면 여러 에이전트의 답변은 평균적인 문장으로 합쳐집니다. 이때 가장 먼저 사라지는 것은 소수 의견입니다. 그런데 업무 시스템에서 중요한 리스크는 다수결로 나오지 않는 경우가 많습니다.
예를 들어 다섯 개 관점 중 네 개가 “배포 가능”이라고 말하고, 보안 관점 하나만 “권한표가 없어 배포 판단 불가”라고 말할 수 있습니다. 이때 judge가 다수 의견을 따라 “대체로 배포 가능”이라고 정리하면 위험합니다. 보안 관점의 지적은 소수 의견이지만 high severity 리스크입니다.
그래서 judge 출력에는 최소한 다음 항목이 있어야 합니다.
{
"accepted_findings": [],
"rejected_findings": [],
"conflicts": [],
"minority_risks": [],
"missing_evidence": [],
"requires_human_decision": [],
"final_decision_basis": []
}충돌 지점 살피기
여러 에이전트를 만들면 자연스럽게 토론 구조를 떠올립니다. 각 에이전트가 자기 의견을 내고, 서로 반박하고, 마지막에 합의하는 흐름입니다.
하지만 처음부터 토론을 시키면 독립성이 쉽게 무너집니다. 한 에이전트의 그럴듯한 답변이 다른 에이전트에게 영향을 줄 수 있습니다. 틀린 의견이 다수의 합의처럼 보일 수도 있습니다. 비슷한 표현이 반복되면서 실제 쟁점이 흐려질 수도 있습니다.
안정적인 흐름은 조금 다릅니다.
1. 각 관점이 서로의 답을 보지 않고 1차 분석한다.
2. judge가 결과를 모아 충돌, 누락, 근거 부족을 정리한다.
3. 필요한 관점에만 다시 질문한다.
4. 최종 산출물을 만든다.
최종 답변을 만들기 전에 충돌을 먼저 봐야 합니다.
예를 들어 UX 관점은 사용자가 클릭 한 번으로 작업을 실행할 수 있어야 한다고 말할 수 있습니다. 보안 관점은 승인 없는 실행이 위험하다고 말할 수 있습니다. 둘 중 하나만 맞는 상황이 아닐 수 있습니다. 저위험 작업은 바로 실행하고, 민감정보 조회, 외부 발송, 비용 발생, 권한 변경 같은 작업은 승인 단계를 거치도록 설계하면 됩니다.
judge는 이런 충돌을 설계 결정으로 바꿔야 합니다.
충돌 지점:
- UX 관점은 즉시 실행을 선호함
- 보안 관점은 승인 없는 실행을 고위험으로 봄
판단:
- 저위험 작업은 즉시 실행
- 민감정보, 외부 발송, 비용 발생, 권한 변경 작업은 승인 필요
설계 반영:
- 작업 위험도 분류 추가
- 고위험 작업에 승인 단계 추가
- 승인 로그 저장
이 과정이 없으면 멀티에이전트 시스템은 여러 의견을 모아 평균적인 답변을 만드는 데 그칩니다. 충돌을 드러내고, 그 충돌을 제품 결정으로 바꿔야 실제로 쓸 만한 결과물이 나옵니다.
모델 다양성과 페르소나 다양성을 분리하기
멀티에이전트 시스템에서 다양성은 여러 층위로 나뉩니다.
같은 모델을 여러 번 호출할 수도 있습니다. 같은 모델에 서로 다른 페르소나를 줄 수도 있습니다. 서로 다른 모델을 조합할 수도 있습니다. 모델과 페르소나를 모두 다르게 줄 수도 있습니다.
최근 연구들은 이 차이를 나눠서 봅니다. 같은 모델과 같은 프롬프트를 쓰는 동질적인 에이전트는 출력이 빠르게 비슷해지고, 한계효용이 빨리 줄어듭니다. 서로 다른 모델, 다른 프롬프트, 다른 도구, 다른 출력 형식을 가진 에이전트는 더 보완적인 증거를 만들 수 있습니다.
페르소나 다양성과 모델 다양성을 분리한 실험도 있습니다. 같은 모델에 서로 다른 페르소나를 준 경우, 서로 다른 모델에 같은 프롬프트를 준 경우, 서로 다른 모델에 서로 다른 페르소나를 준 경우를 비교합니다. 이 흐름의 연구에서는 모델 다양성이 페르소나 다양성보다 더 큰 효과를 만들고, 둘을 함께 적용했을 때 가장 좋은 결과가 나오는 경향이 보고됩니다.
다만 다양성 자체에 너무 기대면 위험합니다. 낮은 품질의 모델을 많이 섞으면 최종 결과가 나빠질 수 있습니다. 여러 모델을 섞는 것보다 가장 강한 모델의 여러 출력을 합성하는 편이 더 나은 경우도 보고됩니다. 결국 중요한 것은 “서로 다름”과 “각 출력의 품질” 사이의 균형입니다.
여기서 주의할 점은 다양성을 무조건 늘리는 것이 답은 아니라는 점입니다. Agent Scaling 연구는 동질적인 에이전트를 늘리면 효용이 빨리 줄고, 서로 다른 모델/프롬프트/도구처럼 이질적인 채널이 있을 때 보완적 증거가 생긴다고 설명합니다. 반면 Rethinking Mixture-of-Agents는 여러 모델을 섞는 방식이 항상 유리하지 않으며, 품질이 낮은 모델이 섞이면 단일 강한 모델의 여러 출력을 합성하는 방식보다 성능이 떨어질 수 있음을 보여줍니다.
따라서 다양성은 다른 이름의 에이전트가 아니라 서로 다른 고품질 증거로 봐야 합니다.
좋은 다양성은 다음 특징을 가집니다.
- 서로 다른 오류를 잡는다.
- 출력이 과하게 겹치지 않는다.
- 각 관점의 답변 품질이 충분히 높다.
- judge가 비교할 수 있는 형식으로 나온다.
- 최종 결과물에 실제로 반영된다.
나쁜 다양성은 아래와 같습니다.
- 역할명만 다르고 같은 말을 반복한다.
- 각 에이전트가 일반론을 길게 쓴다.
- 책임 범위가 겹친다.
- judge가 무엇을 믿어야 할지 판단하지 못한다.
- 최종 결과물에는 거의 반영되지 않는다.
에이전트가 많아졌는데 사용자가 읽어야 할 텍스트만 늘어난다면 설계가 잘못된 것입니다.
관점 카드 템플릿
멀티에이전트 시스템을 설계할 때 바로 에이전트를 실행하기보다 관점 카드를 먼저 만드는 편이 좋습니다.
관점 이름:
- 이 관점은 무엇을 판단하는가?
잡아야 하는 실패:
1.
2.
3.
우선적으로 볼 입력:
-
보면 안 되는 것:
-
사용 가능한 도구:
-
출력 형식:
-
판단 불가라고 말해야 하는 조건:
-
다른 관점과 충돌할 가능성이 높은 지점:
-
이 템플릿에서 중요한 항목은 “보면 안 되는 것”과 “판단 불가 조건”입니다.
LLM은 기본적으로 답하려고 합니다. 정보가 부족해도 그럴듯한 문장을 만들 수 있습니다. 업무 시스템에서는 이 성향이 문제가 됩니다. 특히 보안, 법무, 금융, 의료, 데이터 분석처럼 근거가 중요한 영역에서는 모르는 것을 모른다고 말해야 합니다.
예를 들어 보안 관점의 판단 불가 조건은 이렇게 쓸 수 있습니다.
다음 정보가 없으면 권한 안전성을 확정하지 않는다.
- 조직별 권한표
- 문서별 접근 제어 정보
- 사용자 그룹 정보
- 감사 로그 저장 방식
데이터 관점은 다르게 쓸 수 있습니다.
다음 정보가 없으면 자동 매핑 가능 여부를 확정하지 않는다.
- 필수 필드 목록
- 실제 샘플 데이터
- 용어집
- 최신본 판별 기준
이 조건이 있어야 결과물에 불확실성이 남습니다. 불확실성이 남아야 사람이 판단할 수 있습니다.
최종 결과물
flowchart TB
P[최종 산출물 패키지]
P --> A[최종 답변]
P --> E[근거 맵]
P --> AS[가정 목록]
P --> C[충돌 지점]
P --> R[리스크]
P --> U[판단 불가 항목]
P --> T[검증 체크리스트]
P --> L[실행 로그]
P --> W[재실행 가능한 워크플로우]
E --> E1[주장]
E1 --> E2[근거]
E2 --> E3[출처 / 입력 자료]
T --> T1[테스트 질문]
T --> T2[기대 결과]
T --> T3[실패 조건]
L --> L1[관점별 출력]
L --> L2[judge 판단]
L --> L3[사람 수정 이력]멀티에이전트 시스템이 단일 모델 호출보다 더 나은 사용자 경험을 만들려면 최종 답변만 보여줘서는 부족합니다. 사용자는 결과가 왜 그렇게 나왔는지, 무엇이 빠졌는지, 어떤 가정 위에서 만들어졌는지 알아야 합니다.
최종 산출물에는 다음이 함께 있어야 합니다.
- 최종 답변
- 근거 맵
- 가정 목록
- 충돌 지점
- 반대 의견
- 리스크
- 판단 불가 항목
- 검증 체크리스트
- 재실행 가능한 워크플로우
예를 들어 어떤 문서 기반 자동화 시스템을 설계했다고 해보겠습니다. 최종 답변만 쓰면 이렇게 끝날 수 있습니다.
부서별 권한을 분리하고, 승인 후 배포하는 문서 기반 질의응답 앱을 구성합니다.
업무에서는 이 정도로 부족합니다. 사용자는 바로 다음을 묻습니다.
왜 부서별 권한 분리가 필요한가?
어떤 문서 때문에 민감정보 리스크가 생겼는가?
승인자는 누가 되어야 하는가?
아직 판단할 수 없는 부분은 무엇인가?
이 설계가 실제로 잘 작동하는지 어떻게 테스트할 것인가?
결과물이 이런 질문에 답해야 합니다.
결론:
- 부서별 권한 분리가 필요함
근거:
- 업로드 문서에 인사, 정산, 계약 자료가 함께 포함됨
- 사용자 요청에 부서별 접근 차이가 암시되어 있음
- 현재 설계안에는 문서 접근 제어가 없음
가정:
- 사용자는 부서별로 다른 문서 접근 권한을 가진다
- 문서 저장소는 권한 메타데이터를 제공할 수 있다
리스크:
- 단일 문서 저장소로 구성하면 과권한 접근 가능성 있음
판단 불가:
- 실제 조직 권한표가 제공되지 않아 세부 권한 매핑은 보류
검증:
- 영업팀 사용자가 인사 문서에 질문했을 때 접근이 차단되는지 테스트
이런 형태가 되면 사용자가 수정할 수 있습니다. 최종 답변을 믿거나 버리는 선택지만 남는 것이 아니라, 근거와 가정을 보고 판단할 수 있습니다.
실행 기록이 남기기
멀티에이전트 시스템은 결과만 보면 디버깅하기 어렵습니다. 같은 요청이라도 어떤 관점이 어떤 입력을 봤는지, 어떤 도구를 썼는지, 어떤 근거를 채택했는지에 따라 결과가 달라집니다.
그래서 각 실행에는 다음 기록이 남아야 합니다.
- run_id
- perspective_id
- 사용한 모델과 프롬프트 버전
- 사용한 입력 자료
- 사용한 도구
- 생성한 근거
- 판단 불가로 남긴 항목
- judge가 채택한 항목
- judge가 버린 항목
- 사람이 수정한 항목
이 기록이 없으면 실패를 고치기 어렵습니다. 답변이 이상하다는 피드백을 받아도, 요구사항 관점이 놓친 것인지, 데이터 관점이 잘못 본 것인지, judge가 잘못 합친 것인지 구분할 수 없습니다.
멀티에이전트 구조는 답변 생성 구조이기도 하지만, 동시에 의사결정 로그를 남기는 구조여야 합니다.
ablation 평가
멀티에이전트 시스템은 쉽게 과대평가됩니다. 여러 에이전트가 각자 말하고, judge가 종합하면 복잡한 시스템처럼 보입니다. 하지만 단일 모델보다 실제로 나은지는 따로 검증해야 합니다.
최소한 다음 비교군은 필요합니다.
A. 단일 모델 1회 호출
B. 같은 모델 여러 번 호출 후 voting 또는 merge
C. 같은 모델 + 여러 페르소나
D. 여러 모델 + 같은 관점
E. 여러 모델 + 여러 관점
F. 여러 관점 + judge + 검증 리포트
이렇게 나눠야 무엇이 성능을 올렸는지 볼 수 있습니다.
성능이 좋아졌다면 그 이유가 페르소나 때문인지, 모델 다양성 때문인지, 여러 번 샘플링했기 때문인지, judge가 좋아서인지 구분해야 합니다. 이 구분 없이 “멀티에이전트가 좋다”고 말하면 제품 설계가 흐려집니다.
평가 지표도 구체적으로 잡아야 합니다.
- 정답성
- 근거 정확도
- 누락 요구사항 수
- 고유 이슈 발견 수
- 중복 이슈 비율
- 잘못된 확정 표현 수
- 판단 불가 처리 품질
- 수정 소요 시간
- 비용
- 지연 시간
- 재실행 일관성
특히 고유 이슈 발견 수와 중복 이슈 비율을 같이 봐야 합니다.
다섯 개의 에이전트가 모두 비슷한 문제만 지적한다면 관점이 제대로 나뉘지 않은 것입니다. 어떤 관점을 제거했을 때 최종 품질이 떨어진다면 그 관점은 실제로 기여하고 있는 것입니다.
제거해도 품질이 그대로인 관점은 정리해야 합니다. 멀티에이전트 시스템에서도 가지치기가 필요합니다.
실패 지도 그리기
멀티에이전트 시스템을 만들 때 먼저 정해야 할 것은 에이전트 수가 아닙니다. 먼저 이 작업이 어디서 실패할 수 있는지 봐야 합니다.
문서 기반 업무라면 문서 최신본, 필드 매핑, 권한, 출처, 승인, 검증이 주요 실패 지점이 될 수 있습니다.
데이터 분석 업무라면 지표 정의, 데이터 조인, 집계 기준, 기간 필터, 이상치, 시각화 해석이 주요 실패 지점이 될 수 있습니다.
코딩 업무라면 요구사항 오해, 기존 코드와의 충돌, 테스트 누락, 보안 취약점, 배포 리스크가 주요 실패 지점이 될 수 있습니다.
실패 지도가 나오면 그때 관점을 정합니다.
실패 지점:
- 요구사항 누락
- 데이터 매핑 실패
- 권한 위반
- 구현 불가능한 설계
- 운영 검증 불가
필요한 관점:
- 요구사항 분석
- 데이터 매핑
- 보안 감사
- 구현 검증
- 품질 평가
이 순서가 중요합니다. 직무명을 먼저 나누면 역할극으로 흐르기 쉽습니다. 실패 지점을 먼저 나누면 각 관점의 책임이 선명해집니다.
마무리
OpenRouter Fusion 같은 사례는 멀티에이전트 시스템을 다시 보게 만듭니다. 여러 모델을 호출하는 기능은 점점 흔해질 것입니다. 더 중요한 차이는 그 답변들을 어떻게 비교하고, 어떤 기준으로 버리고, 무엇을 근거로 최종 결과를 만들지에서 생깁니다.
에이전트를 많이 만드는 것보다 먼저 봐야 할 질문들이 있습니다.
이 작업은 어디서 조용히 실패할 수 있는가?
그 실패를 잡기 위해 어떤 관점이 필요한가?
각 관점은 어떤 입력을 봐야 하는가?
각 관점은 무엇을 모른다고 말해야 하는가?
judge는 합의보다 충돌을 먼저 드러내는가?
최종 결과물에는 근거, 가정, 리스크, 검증 방법이 남는가?
관점 하나를 제거했을 때 품질이 실제로 떨어지는가?
이 질문에 답하지 않은 멀티에이전트 시스템은 에이전트 수를 늘려도 큰 차이를 만들기 어렵습니다. 반대로 각 관점이 서로 다른 실패를 잡고, judge가 충돌과 근거를 구조화하고, 사용자가 그 결과를 수정할 수 있다면 멀티에이전트 구조는 단일 모델 호출보다 더 나은 사용자 경험을 만들 수 있습니다.
결국 설계의 출발점은 단순합니다.
참고한 자료
- OpenRouter, “Surpassing Frontier Performance with Fusion”
- “Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity”
- “Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?”
- “Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models”
- “Can LLM Agents Really Debate? A Controlled Study of Multi-Agent Debate in Logical Reasoning”

![[논문 리뷰] LLM 모델은 답하기 전에 성공 가능성을 알고 있을까?](https://images.unsplash.com/photo-1604134774179-44e6adb65dd9?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHN3YW58ZW58MHx8fHwxNzcwODE5NjExfDA&ixlib=rb-4.1.0&q=80&w=600)

